101081
•
20분 읽기
•


PageRank 알고리즘(또는 줄여서 PR)은 90년대 후반 스탠포드 대학의 Larry Page와 Sergey Brin이 개발한 웹페이지 순위 시스템입니다. PageRank는 실제로 Page와 Brin이 Google 검색 엔진을 만든 기반이었습니다.
그 이후로 수년이 지났으며 물론 Google의 순위 알고리즘은 훨씬 더 복잡해졌습니다. 아직도 PageRank를 기반으로 하고 있나요? PageRank가 순위에 정확히 얼마나 영향을 미치는지, 이것이 순위가 하락한 이유 중 하나일 수 있으며, SEO는 앞으로 무엇을 준비해야 합니까? 이제 우리는 그림을 명확하게 하기 위해 PageRank에 관한 모든 사실과 미스터리를 찾아 요약할 것입니다. 글쎄, 우리가 할 수 있는 만큼.
위에서 언급한 바와 같이, 대학 연구 프로젝트에서 브린과 페이지는 웹페이지의 권위를 평가하는 시스템을 고안하려고 했습니다. 그들은 페이지에 대한 신뢰 투표 역할을 하는 링크에 시스템을 구축하기로 결정했습니다. 해당 메커니즘의 논리에 따르면 페이지에 더 많은 외부 리소스가 연결될수록 사용자에게 더 많은 가치 있는 정보가 제공됩니다. 그리고 PageRank(들어오는 링크의 양과 질을 기준으로 계산된 0에서 10까지의 점수)는 인터넷에서 페이지의 상대적 권위를 나타냅니다.
PageRank가 어떻게 작동하는지 살펴보겠습니다. 한 페이지(A)에서 다른 페이지(B)로의 각 링크는 소위 투표를 하며, 투표의 가중치는 페이지 A로 연결되는 모든 페이지의 총체적인 가중치에 따라 달라집니다. 그리고 우리는 계산할 때까지 그 가중치를 알 수 없습니다. 그래서 프로세스는 주기적으로 진행됩니다.
원래 PageRank의 수학 공식은 다음과 같습니다.
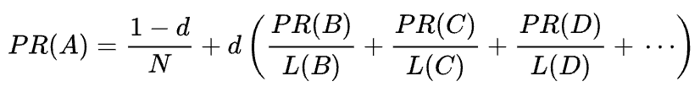
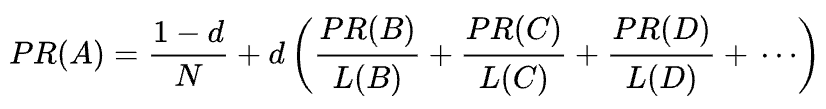
여기서 A, B, C 및 D 는 일부 페이지이고 L 은 각 페이지에서 나가는 링크 수이며 N 은 컬렉션(예: 인터넷)의 총 페이지 수입니다.
d 의 경우, d 는 소위 감쇠 인자(damping Factor) 입니다. PageRank가 무작위로 페이지에 접속하여 링크를 클릭하는 사용자의 행동을 시뮬레이션하여 계산된다는 점을 고려하여 이 감쇠 d 인자를 사용자가 지루해하고 페이지를 떠날 확률로 적용합니다.
공식에서 볼 수 있듯이 해당 페이지를 가리키는 페이지가 없으면 해당 PR은 0이 아니지만
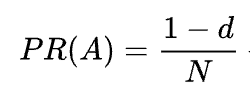
사용자가 다른 페이지가 아닌 북마크를 통해 이 페이지에 액세스할 가능성이 있기 때문입니다.
처음에 PageRank 점수는 Google 툴바에 공개적으로 표시되었으며 각 페이지의 점수는 0에서 10까지였으며 아마도 로그 척도로 표시되었을 것입니다.
당시 Google의 순위 알고리즘은 정말 간단했습니다. 높은 PR과 키워드 밀도는 페이지가 SERP에서 높은 순위를 매기는 데 필요한 유일한 두 가지 요소였습니다. 그 결과 웹페이지는 키워드로 가득 찼고, 웹사이트 소유자는 스팸성 백링크를 인위적으로 늘려 페이지랭크를 조작하기 시작했습니다. 그것은 쉬운 일이었습니다. 웹 사이트 소유자에게 "도움의 손길"을 제공하기 위해 링크 팜과 링크 판매가 있었습니다.
Google은 링크 스팸에 맞서 싸우기로 결정했습니다. 2003년에 구글은 링크 조작 혐의로 광고 네트워크 회사인 서치킹(SearchKing)의 웹사이트를 처벌했습니다. SearchKing은 Google을 고소했지만 Google이 승리했습니다. 이는 Google이 모든 사람의 링크 조작을 제한하려고 시도했지만 아무 소용이 없었습니다. 링크팜은 이제 막 지하화되었고 그 양은 크게 늘어났습니다.
게다가 블로그에 올라오는 스팸성 댓글도 늘어났다. 봇은 예를 들어 WordPress 블로그의 댓글을 공격하고 엄청난 수의 "여기를 클릭하여 구매하는 마법의 약" 댓글을 남겼습니다. 댓글의 스팸 및 PR 조작을 방지하기 위해 Google은 2005년에 nofollow 태그를 도입했습니다. 그리고 다시 한번 Google이 링크 조작 전쟁에서 성공하기 위해 의도했던 것이 왜곡된 방식으로 구현되었습니다. 사람들은 PageRank를 필요한 페이지에 인위적으로 연결하기 위해 nofollow 태그를 사용하기 시작했습니다. 이 전술은 PageRank 조각으로 알려졌습니다.
PR 조각을 방지하기 위해 Google은 PageRank 흐름 방식을 변경했습니다. 이전에는 페이지에 nofollow 및 dofollow 링크가 모두 있는 경우 해당 페이지의 모든 PR 볼륨이 dofollow 링크로 연결된 다른 페이지로 전달되었습니다. 2009년에 Google은 페이지에 있는 모든 링크 간에 페이지의 PR을 균등하게 나누기 시작했지만 dofollow 링크에 제공된 공유만 전달했습니다.


PageRank 조각 작업을 마친 Google은 링크 스팸 전쟁을 멈추지 않았고 결과적으로 PageRank 점수를 대중의 눈에서 없애기 시작했습니다. 먼저 Google은 PR 점수가 표시되는 Google 툴바 없이 새로운 Chrome 브라우저를 출시했습니다. 그런 다음 Google Search Console에서 PR 점수 보고를 중단했습니다. 그런 다음 Firefox 브라우저는 Google 툴바 지원을 중단했습니다. 2013년에 PageRank가 Internet Explorer용으로 마지막으로 업데이트되었으며, 2016년에 Google은 대중을 대상으로 툴바를 공식적으로 종료했습니다.


Google이 링크 계획에 맞서기 위해 사용한 또 다른 방법은 의심스러운 백링크 프로필이 있는 웹사이트의 순위를 낮추는 Penguin 업데이트 였습니다. 2012년에 출시된 Penguin은 Google 실시간 알고리즘의 일부가 된 것이 아니라 수시로 업데이트되어 검색 결과에 다시 적용되는 '필터'였습니다. 웹사이트가 Penguin에 의해 불이익을 받는 경우 SEO는 링크 프로필을 주의 깊게 검토하고 유해한 링크를 제거하거나 거부 목록(당시에는 PageRank를 계산할 때 무시할 수신 링크를 Google에 알려주기 위해 도입된 기능)에 추가해야 했습니다. 그런 식으로 링크 프로필을 감사한 후 SEO는 Penguin 알고리즘이 데이터를 다시 계산할 때까지 반년 정도 기다려야 했습니다.
2016년에 Google은 Penguin을 핵심 순위 알고리즘의 일부로 만들었습니다. 그 이후로 실시간으로 작업하여 알고리즘을 통해 스팸을 훨씬 더 성공적으로 처리해 왔습니다.
동시에 Google은 링크 수보다는 품질을 촉진하기 위해 노력하여 링크 구성표에 대한 품질 지침을 엄격히 준수했습니다.
이제 PageRank의 과거는 끝났습니다. 지금 무슨 일이 일어나고 있나요?
2019년에 전직 Google 직원은 원래 PageRank 알고리즘이 2006년 이후로 사용되지 않았으며 인터넷이 성장함에 따라 리소스 집약적이지 않은 다른 알고리즘으로 대체되었다고 말했습니다. 2006년 Google이 새로운 웹 링크 그래프에서 거리를 사용하여 페이지 순위 생성 특허를 제출한 것처럼 이는 사실일 수도 있습니다.
예, 그렇습니다. 2000년대 초반의 페이지랭크는 아니지만, 구글은 계속해서 링크 권한에 크게 의존하고 있습니다. 예를 들어, 전 Google 직원인 Andrey Lipattsev는 2016년에 이에 대해 언급했습니다. Google Q&A 행아웃에서 한 사용자가 그에게 Google이 사용하는 주요 순위 신호가 무엇인지 물었습니다. 안드레이의 대답은 매우 간단했습니다.

나는 그것이 무엇인지 말해 줄 수 있습니다. 귀하의 사이트를 가리키는 콘텐츠와 링크입니다.
2020년에 John Mueller는 다시 한번 다음과 같이 확인했습니다.

예, 우리는 다른 많은 신호 중에서 내부적으로 PageRank를 사용합니다. 원본 논문과 완전히 동일하지는 않으며, 많은 단점(예: 거부된 링크, 무시된 링크 등)이 있으며, 다시 말하지만 우리는 훨씬 더 강력할 수 있는 많은 다른 신호를 사용합니다.
보시다시피 PageRank는 여전히 살아 있으며 웹에서 페이지 순위를 매길 때 Google에서 적극적으로 사용합니다.
흥미로운 점은 Google 직원이 다른 Google 순위 요소가 매우 많다는 사실을 계속해서 상기시켜 준다는 것입니다. 그러나 우리는 이것을 약간의 소금으로 봅니다. Google이 링크 스팸과 싸우기 위해 얼마나 많은 노력을 기울였는지를 고려하면 SEO의 관심을 조작에 취약한 요소(백링크와 마찬가지로)에서 벗어나 순진하고 좋은 것에 관심을 집중시키는 것이 Google의 이익이 될 수 있습니다. 그러나 SEO는 행 사이를 읽는 데 능숙하기 때문에 PageRank를 강력한 순위 신호로 계속 고려하고 가능한 모든 방법으로 백링크를 늘립니다. 그들은 오래 전과 마찬가지로 여전히 PBN을 사용하고 회색 모자 계층 링크 구축을 연습하고 링크를 구매하는 등의 작업을 수행합니다. PageRank가 살아 있으면 링크 스팸도 살아납니다. 우리는 그 어떤 것도 권장하지 않습니다. 그러나 이것이 바로 SEO 현실이며, 우리는 그것을 이해해야 합니다.
글쎄요, 지금의 PageRank는 20년 전의 PageRank가 아니라는 생각을 가지셨을 것입니다.
PR의 주요 현대화 중 하나는 위에서 간략하게 언급한 Random Surfer 모델에서 2012년 Reasonable Surfer 모델로 전환한 것입니다. Reasonable Surfer는 사용자가 페이지에서 혼란스럽게 행동하지 않는다고 가정하고 페이지에서 관심 있는 링크만 클릭합니다. 순간. 예를 들어, 블로그 기사를 읽을 때 바닥글의 이용 약관 링크보다는 기사 내용의 링크를 클릭할 가능성이 더 높습니다.
또한 Reasonable Surfer는 링크의 매력을 평가할 때 다양한 다른 요소를 잠재적으로 사용할 수 있습니다. 이러한 모든 요소는 Bill Slawski의 기사에서 주의 깊게 검토 되었지만 저는 SEO가 더 자주 논의하는 두 가지 요소에 초점을 맞추고 싶습니다. 링크 위치와 페이지 트래픽입니다. 이러한 요인에 대해 무엇을 말할 수 있습니까?
링크는 콘텐츠, 탐색 메뉴, 작성자 약력, 바닥글 및 실제로 페이지에 포함된 모든 구조적 요소 등 페이지의 어느 곳에나 위치할 수 있습니다. 그리고 링크 위치가 다르면 링크 값에 영향을 미칩니다. John Mueller는 기본 콘텐츠 내에 배치된 링크가 다른 모든 콘텐츠보다 더 중요하다고 말하면서 다음과 같이 확인했습니다.
이는 메뉴, 사이드바, 바닥글, 헤더가 아닌 기본 콘텐츠, 즉 이 페이지가 실제로 다루는 콘텐츠가 있는 페이지 영역입니다. 그런 다음 우리는 이를 고려하고 시도합니다. 해당 링크를 사용하려면.
따라서 바닥글 링크와 탐색 링크는 가중치가 덜하다고 합니다. 그리고 이 사실은 때때로 Google 대변인뿐만 아니라 실제 사례를 통해 확인됩니다.
최근 BrightonSEO의 Martin Hayman이 제시한 사례에서 Martin은 탐색 메뉴에 이미 있는 링크를 페이지의 기본 콘텐츠에 추가했습니다. 그 결과 해당 카테고리 페이지와 링크된 페이지의 트래픽이 25% 증가했습니다.
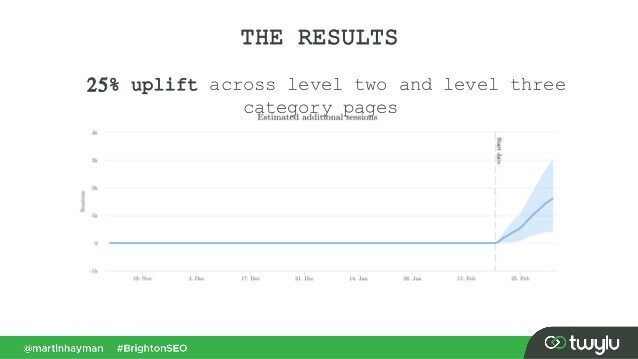
이 실험은 콘텐츠 링크가 다른 링크보다 더 많은 가중치를 전달한다는 것을 증명합니다.
작성자 약력의 링크와 관련하여 SEO는 약력 링크가 중요하지만 콘텐츠 링크보다 가치가 낮다고 가정합니다. 여기에는 많은 증거가 없지만 Google이 백링크를 위해 과도한 게스트 블로깅과 적극적으로 싸울 때 Matt Cutts가 말한 내용에 대한 증거가 없습니다.
John Mueller는 Search Console Central 행아웃 중 하나에 링크 주스를 전달하는 측면에서 Google이 트래픽과 사용자 행동을 처리하는 방식을 명확히 했습니다. 한 사용자가 Mueller에게 Google이 링크 품질을 평가할 때 클릭 확률과 링크 클릭 수를 고려하는지 물었습니다. Mueller의 답변에서 얻은 주요 내용은 다음과 같습니다.
Google은 링크 품질을 평가할 때 링크 클릭수와 클릭 확률을 고려하지 않습니다.
Google은 참조와 같은 콘텐츠에 링크가 추가되는 경우가 많으며 사용자가 발견한 모든 링크를 클릭할 것으로 예상되지 않는다는 점을 이해합니다.
그럼에도 불구하고 SEO는 항상 그렇듯이 Google이 말하는 모든 것을 맹목적으로 믿고 계속 실험할 가치가 있는지 의심합니다. 그래서 Ahrefs의 사람들은 SERP의 페이지 위치가 트래픽이 많은 페이지의 백링크 수와 연결되어 있는지 확인하기 위한 연구를 수행했습니다. 연구에 따르면 상관관계가 거의 없는 것으로 나타났습니다. 게다가 일부 상위 페이지에는 트래픽이 많은 페이지의 백링크가 전혀 없는 것으로 나타났습니다.
이 연구는 John Mueller의 말과 비슷한 방향을 제시합니다. SERP에서 높은 순위를 얻기 위해 페이지에 대한 트래픽 생성 백링크를 구축할 필요가 없습니다. 반면에 추가 트래픽은 어떤 웹사이트에도 해를 끼치지 않았습니다. 여기서 유일한 메시지는 트래픽이 많은 백링크가 Google 순위에 영향을 미치지 않는 것 같다는 것입니다.
기억하시는 것처럼 Google은 링크 스팸에 맞서기 위한 방법으로 2005년에 nofollow 태그를 도입했습니다. 오늘은 뭔가 달라졌나요? 사실 맞아요.
첫째, Google은 최근 두 가지 유형의 nofollow 속성을 더 도입했습니다. 그 전에 Google은 블로그 댓글이든 유료 광고이든 PageRank 계산에 참여하고 싶지 않은 모든 백링크를 nofollow 로 표시할 것을 제안했습니다. 현재 Google에서는 유료 및 제휴 링크에 rel="sponsored"를 사용하고 사용자 생성 콘텐츠에 rel="ugc"를 사용할 것을 권장합니다.

흥미로운 점은 이러한 새 태그가 필수가 아니라는 점입니다(적어도 아직은 아님). Google은 모든 rel=”nofollow”를 rel="sponsored" 및 rel=”ugc” 로 수동으로 변경할 필요가 없다고 지적합니다. 이 두 가지 새로운 속성은 이제 일반 nofollow 태그와 동일한 방식으로 작동합니다.
둘째, Google은 이제 페이지 색인을 생성할 때 nofollow 태그와 새로운 태그인 스폰서 및 ugc가 지시문이 아닌 힌트로 처리된다고 말합니다.
들어오는 링크 외에도 나가는 링크, 즉 귀하의 페이지에서 다른 페이지를 가리키는 링크도 있습니다.
많은 SEO는 나가는 링크가 순위에 영향을 미칠 수 있다고 믿고 있지만 이러한 가정은 SEO 신화 로 취급되어 왔습니다. 그러나 이와 관련하여 살펴볼 흥미로운 연구가 하나 있습니다.
Reboot Online은 2015년에 실험을 수행하고 2020년에 다시 실행했습니다. 그들은 권위가 높은 페이지로 나가는 링크가 SERP에서 페이지 위치에 영향을 미치는지 알아내고 싶었습니다. 그들은 존재하지 않는 키워드인 Phylandocic에 최적화된 300단어 기사로 10개의 웹사이트를 만들었습니다. 5개의 웹사이트에는 나가는 링크가 전혀 없었고, 5개의 웹사이트에는 고위급 리소스에 대한 나가는 링크가 포함되어 있었습니다. 그 결과, 권위 있는 외부 링크가 있는 웹사이트가 가장 높은 순위를 차지하기 시작했고, 링크가 전혀 없는 웹사이트가 가장 낮은 순위를 차지했습니다.
.png)
한편으로, 이 연구 결과는 나가는 링크가 페이지 위치에 영향을 미친다는 것을 알려줍니다. 반면, 연구의 검색어는 완전히 새로운 것이며 웹사이트의 콘텐츠는 의학 및 약물을 주제로 합니다. 따라서 쿼리가 YMYL로 분류될 가능성이 높습니다. 그리고 Google은 YMYL 웹사이트에서 EAT의 중요성을 여러 번 언급했습니다. 따라서 아웃링크는 EAT 신호로 처리되어 페이지에 실제로 정확한 콘텐츠가 있음을 증명할 수 있습니다.
일반적인 쿼리( YMYL 아님)에 대해 John Mueller는 나가는 링크가 사용자에게 좋기 때문에 콘텐츠에서 외부 소스로 연결하는 것을 두려워할 필요가 없다고 여러 번 말했습니다.
게다가 나가는 링크는 스팸으로부터 웹을 필터링할 때 Google AI가 고려할 수 있으므로 SEO에도 도움이 될 수 있습니다. 스팸 페이지에는 나가는 링크가 전혀 없는 경향이 있기 때문입니다. 동일한 도메인에 있는 페이지로 연결되거나(SEO에 대해 생각하는 경우) 유료 링크 만 포함됩니다. 따라서 신뢰할 수 있는 리소스에 대한 링크를 연결하면 귀하의 페이지가 스팸 페이지가 아니라는 점을 Google에 보여주는 것입니다.
나가는 링크가 너무 많으면 Google에서 수동 처벌을 줄 수 있다는 의견이 한때 있었지만 John Mueller는 나가는 링크가 분명히 일부 링크 교환 체계의 일부이고 웹사이트가 일반적으로 다음과 같은 경우에만 가능하다고 말했습니다. 품질이 좋지. Google이 당연하다는 뜻으로 무엇을 의미하는지는 사실 미스터리이므로 상식, 고품질 콘텐츠, 기본 SEO를 염두에 두세요.
PageRank가 존재하는 한 SEO는 이를 조작할 수 있는 새로운 방법을 찾을 것입니다.
2012년에는 Google이 링크 조작 및 스팸에 대한 수동 조치를 발표할 가능성이 더 높았습니다. 그러나 이제는 잘 훈련된 스팸 방지 알고리즘을 통해 Google은 PageRank를 계산할 때 전체 웹사이트의 순위를 전반적으로 낮추는 대신 특정 스팸 링크를 무시할 수 있습니다. 존 뮬러가 말했듯이,
수년에 걸쳐 수집된 임의의 링크가 반드시 해로운 것은 아닙니다. 우리도 오랫동안 보아왔으며 오래 전의 이상한 웹 낙서 조각을 모두 무시할 수 있습니다.
이는 귀하의 백링크 프로필이 경쟁사에 의해 손상되었을 때 부정적인 SEO 에 대해서도 마찬가지입니다.
일반적으로 우리는 이러한 사항을 자동으로 고려하고 이러한 일이 발생하는 것을 볼 때 자동으로 무시하려고 노력합니다. 대부분의 경우, 나는 그것이 상당히 잘 작동한다고 생각합니다. 나는 그와 관련된 실제 문제를 가진 사람을 거의 보지 못했습니다. 그래서 나는 그것이 대부분 잘 작동한다고 생각합니다. 이러한 링크를 거부하는 것과 관련하여 이것이 귀하의 웹 사이트에 나타나는 일반적인 스팸 링크라면 그다지 걱정하지 않을 것입니다. 아마 우리 스스로 그걸 알아냈을 거예요.
그러나 걱정할 것이 없다는 의미는 아닙니다. 웹사이트의 백링크가 너무 자주 무시되는 경우에도 직접 조치를 받을 가능성이 높습니다. Marie Haynes는 2021년 링크 관리에 대한 조언에서 다음과 같이 말합니다.

직접 조치는 괜찮은 사이트에 너무 큰 규모로 해당 사이트를 가리키는 부자연스러운 링크가 있어 Google 알고리즘이 해당 사이트를 무시하기 어려운 경우를 위해 예약되어 있습니다.
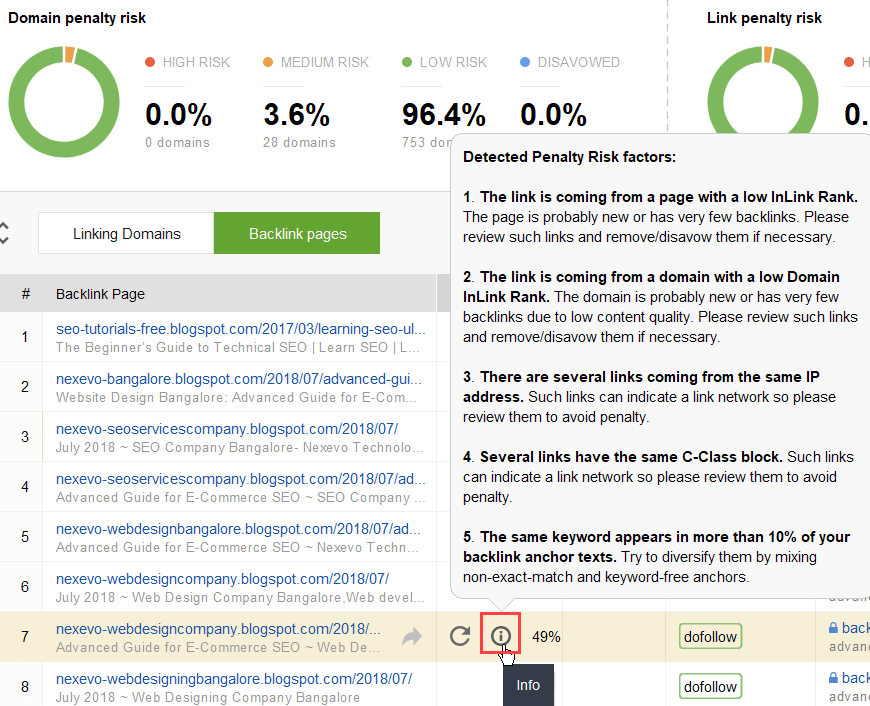
어떤 링크가 문제를 일으키는지 알아내려면 백링크 품질을 확인하는 방법 에 대한 이 가이드를 읽어보세요. 즉, SEO SpyGlass 와 같은 백링크 검사기를 사용할 수 있습니다. 도구에서 백링크 프로필 > 페널티 위험 섹션으로 이동합니다. 위험도가 높거나 중간인 백링크에 주의하세요.
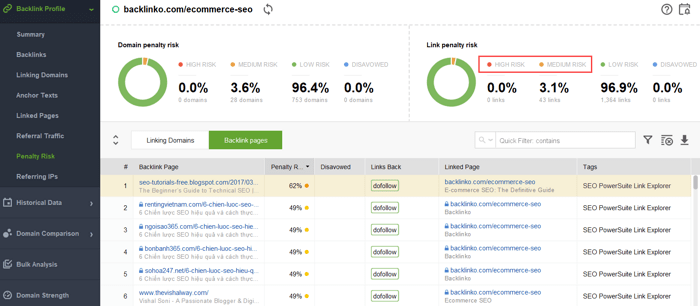
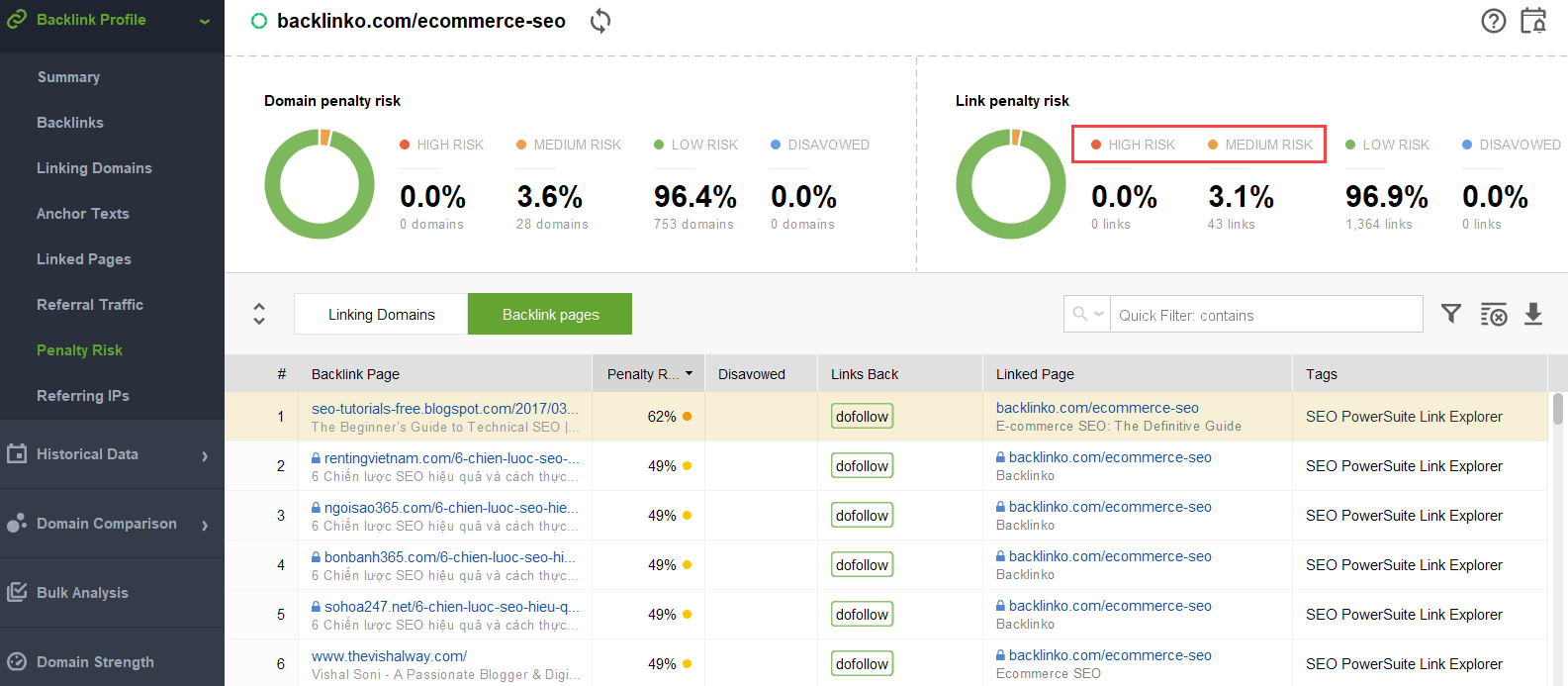
이 링크나 해당 링크가 유해한 것으로 보고된 이유를 자세히 조사하려면 처벌 위험 열에서 i 기호를 클릭하세요. 여기에서 도구가 링크를 불량으로 간주한 이유를 확인하고 링크를 거부할지 여부를 결정하게 됩니다.
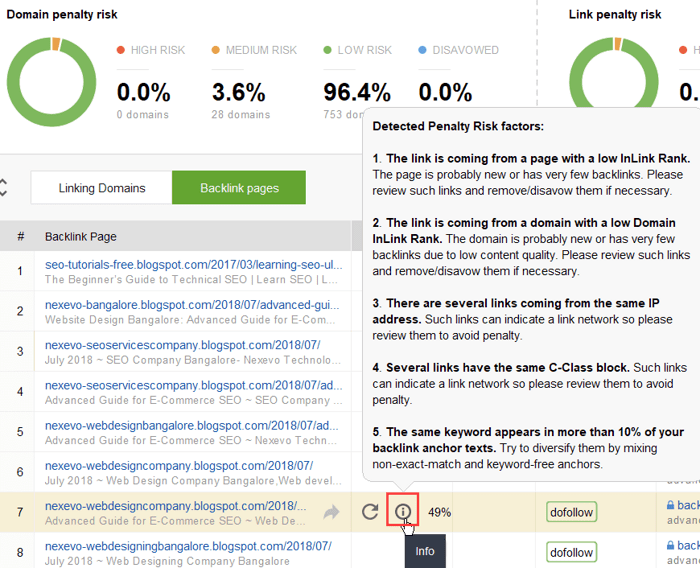
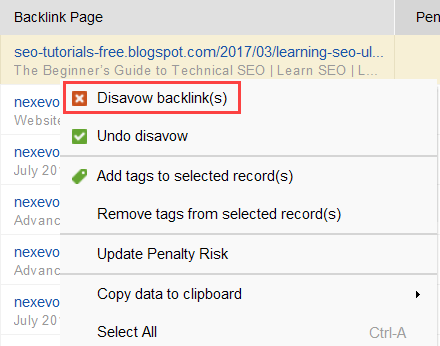
링크 그룹의 링크를 거부하기 로 결정한 경우 링크를 마우스 오른쪽 버튼으로 클릭하고 백링크 거부 옵션을 선택하세요.
제외할 링크 목록을 구성한 후에는 SEO SpyGlass에서 거부 파일을 내보내고 GSC를 통해 Google에 제출할 수 있습니다.
PageRank에 관해 말하면 내부 연결을 언급하지 않을 수 없습니다. 들어오는 PageRank는 우리가 통제할 수 없는 일이지만 PR이 우리 웹사이트 페이지 전체에 퍼지는 방식은 완전히 통제할 수 있습니다.
Google도 내부 연결의 중요성을 여러 번 언급했습니다. John Mueller는 최신 Search Console Central 행아웃 중 하나에서 이 점을 다시 한 번 강조했습니다. 사용자가 일부 웹페이지를 더욱 강력하게 만드는 방법을 문의했습니다. 그리고 존 뮬러는 다음과 같이 말했습니다.
...내부 연결에 도움을 줄 수 있습니다. 따라서 웹 사이트 내에서 더 강조하고 싶은 페이지를 강조 표시하고 해당 페이지가 내부적으로 잘 연결되어 있는지 확인할 수 있습니다. 그리고 그다지 중요하지 않은 페이지일 수도 있으므로 내부적으로 링크가 약간 덜한지 확인하세요.
내부 연결은 많은 의미를 갖습니다. 이는 웹사이트의 여러 페이지 간에 들어오는 PageRank를 공유하는 데 도움이 되므로 실적이 저조한 페이지를 강화하고 웹사이트를 전반적으로 더욱 강력하게 만듭니다.
내부 연결에 대한 접근 방식에 관해서는 SEO에는 다양한 이론이 있습니다. 널리 사용되는 접근 방식 중 하나는 웹사이트 클릭 깊이와 관련이 있습니다. 이 아이디어는 웹사이트의 모든 페이지가 홈페이지에서 최대 3번 클릭할 수 있는 거리에 있어야 한다는 것을 의미합니다. Google도 얕은 웹사이트 구조의 중요성을 여러 번 강조했지만 실제로는 모든 규모가 작은 웹사이트에서는 이 구조가 도달하기 어려운 것으로 보입니다.
또 다른 접근 방식은 중앙 집중식 및 분산형 내부 연결 개념을 기반으로 합니다. Kevin Indig는 다음과 같이 설명합니다.

중앙 집중식 사이트에는 단일 사용자 흐름과 하나의 주요 페이지를 가리키는 유입경로가 있습니다. 분산형 내부 링크가 있는 사이트에는 여러 전환 접점이 있거나 가입 형식이 다릅니다.
중앙 집중식 내부 연결의 경우 소규모 전환 페이지 그룹 또는 하나의 페이지가 있는데 이를 강력하게 만들고 싶습니다. 분산형 내부 링크를 적용하는 경우 모든 웹사이트 페이지가 동일하게 강력하고 동일한 PageRank를 갖고 있어 모든 페이지가 귀하의 검색어에 대해 순위를 매길 수 있기를 바랍니다.
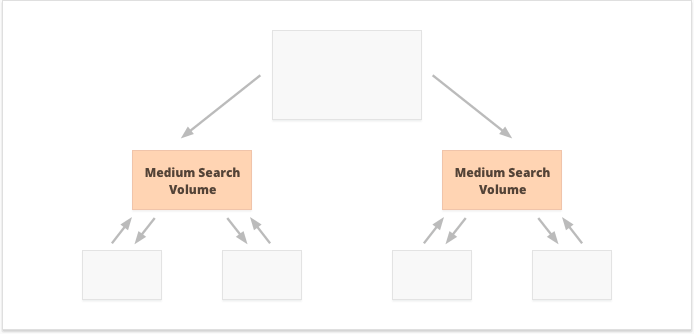
어떤 옵션이 더 낫습니까? 이는 모두 귀하의 웹사이트와 비즈니스 틈새 특성, 그리고 귀하가 타겟팅하려는 키워드 에 따라 달라집니다. 예를 들어, 중앙 집중식 내부 링크는 매우 강력한 페이지 집합을 생성하므로 검색량이 높거나 중간인 키워드에 더 적합합니다.
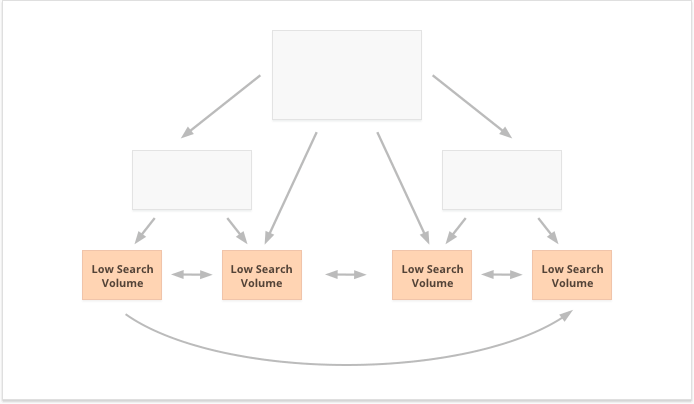
반면, 검색량이 적은 롱테일 키워드는 수많은 웹사이트 페이지에 균등하게 PR을 퍼뜨리기 때문에 분산형 내부 링크에 더 좋습니다.
성공적인 내부 연결의 또 다른 측면은 페이지에서 들어오고 나가는 링크의 균형 입니다. 이런 점에서 많은 SEO에서는 실제로는 PageRank의 역인 CheiRank (CR)를 사용합니다. 그러나 PageRank는 수신된 전력인 반면 CheiRank는 제공되는 링크 전력입니다. 페이지에 대한 PR 및 CR을 계산하면 어떤 페이지에 링크 이상이 있는지 확인할 수 있습니다. 즉, 페이지가 PageRank를 많이 받았지만 조금 더 통과하거나 그 반대인 경우를 알 수 있습니다.
여기서 흥미로운 실험은 Kevin Indig의 링크 이상 현상 평탄화 입니다. 웹 사이트의 모든 페이지에서 들어오고 나가는 PageRank의 균형을 유지하는 것만으로도 매우 인상적인 결과를 얻을 수 있습니다. 여기의 빨간색 화살표는 이상이 수정된 시간을 나타냅니다.
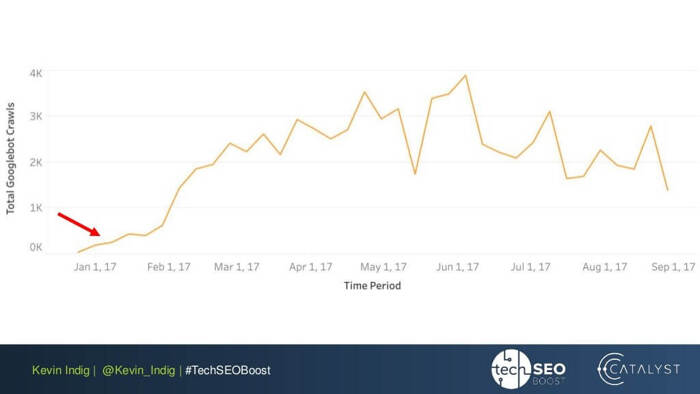
링크 이상 현상만이 PageRank 흐름에 해를 끼칠 수 있는 것은 아닙니다. 힘들게 얻은 PR을 망칠 수 있는 기술적인 문제가 발생하지 않도록 하세요.
고아 페이지. 고아 페이지는 웹사이트의 다른 페이지에 링크되어 있지 않으므로 유휴 상태로 남아 있으며 링크 주스를 받지 못합니다. Google은 해당 항목을 볼 수 없으며 실제로 존재하는지 알지 못합니다.
체인을 리디렉션합니다. Google에서는 이제 리디렉션이 PR의 100%를 통과한다고 말하지만 여전히 긴 리디렉션 체인을 피하는 것이 좋습니다. 첫째, 어쨌든 크롤링 예산을 소모합니다. 둘째, 우리는 구글이 말하는 모든 것을 맹목적으로 믿을 수 없다는 것을 알고 있습니다.
구문 분석할 수 없는 JavaScript의 링크입니다. Google은 이를 읽을 수 없으므로 PageRank를 통과하지 못합니다.
404개의 링크. 404 링크는 아무데도 연결되지 않으므로 PageRank도 아무데도 가지 않습니다.
중요하지 않은 페이지에 대한 링크입니다. 물론 링크가 전혀 없는 페이지를 남겨둘 수는 없지만 페이지가 동일하게 생성되지는 않습니다. 일부 페이지가 덜 중요하다면 해당 페이지의 링크 프로필을 최적화하는 데 너무 많은 노력을 기울이는 것은 합리적이지 않습니다.
페이지가 너무 멀습니다. 페이지가 웹사이트에서 너무 깊숙한 곳에 위치하면 PR을 거의 받지 못하거나 전혀 받지 못할 가능성이 높습니다. Google이 이를 찾아서 색인을 생성하지 못할 수도 있습니다.
귀하의 웹사이트에 이러한 PageRank 위험이 없는지 확인하려면 WebSite Auditor를 사용하여 웹사이트를 감사할 수 있습니다. 이 도구에는 사이트 구조 > 사이트 감사 섹션에 포괄적인 모듈 세트가 포함되어 있어 웹사이트의 전반적인 최적화를 확인하고 긴 리디렉션과 같은 모든 링크 관련 문제를 찾아서 수정할 수 있습니다.
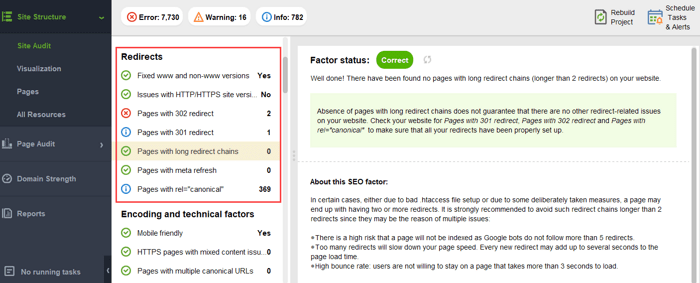
끊어진 링크:
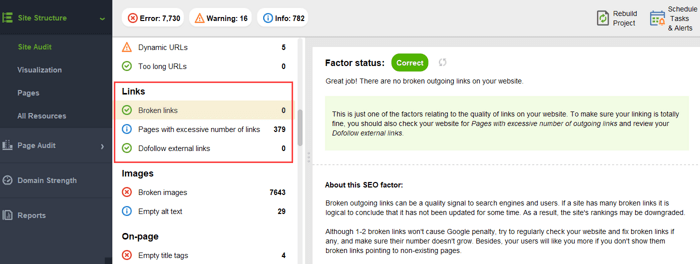
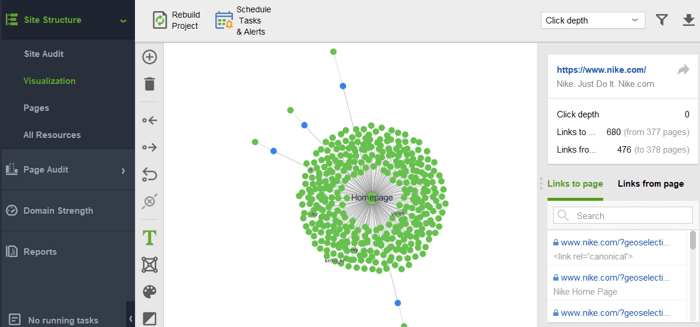
사이트에서 고아 페이지나 너무 멀리 떨어져 있는 페이지를 확인 하려면 사이트 구조 > 시각화 로 전환하세요.
올해 PageRank는 23주년을 맞이했습니다. 그리고 제 생각에는 현재 일부 독자들보다 나이가 더 많은 것 같습니다.:) 하지만 앞으로 PageRank에 어떤 일이 일어날까요? 언젠가는 완전히 사라지게 될까요?
알고리즘에 백링크를 사용하지 않는 인기 검색 엔진을 생각할 때 제가 떠올릴 수 있는 유일한 아이디어는 2014년 Yandex 실험 입니다. 검색 엔진은 알고리즘에서 백링크를 삭제하면 마침내 링크 스패머의 조작을 중단하고 그들의 노력을 고품질 웹사이트 제작에 집중하는 데 도움이 될 것이라고 발표했습니다.
대체 순위 요소로 이동하려는 진정한 노력이었을 수도 있고 링크 스팸을 삭제하도록 대중을 설득하려는 시도일 수도 있습니다. 그러나 어쨌든 발표 후 불과 1년 만에 Yandex는 백링크 요소가 시스템에 다시 돌아왔음을 확인했습니다.
그런데 왜 백링크가 검색 엔진에 꼭 필요한가요?
검색 결과를 표시하기 시작한 후 (예: 사용자 행동 및 BERT 조정) 재정렬하기 위한 수많은 다른 데이터 포인트가 있지만 백링크는 초기 SERP를 형성하는 데 필요한 가장 신뢰할 수 있는 권한 기준 중 하나로 남아 있습니다. 여기서 유일한 경쟁자는 아마도 엔터티일 것입니다.
Bill Slawski는 PageRank의 미래에 대한 질문에 다음과 같이 말했습니다.
.png)
Google은 기계 학습과 사실 추출을 탐구하고 기업의 핵심 가치 쌍을 이해하고 있습니다. 이는 의미 검색을 향한 움직임과 구조화된 데이터 및 데이터 품질의 더 나은 사용을 의미합니다.
그럼에도 불구하고 구글은 수십 년간의 개발에 투자한 것을 버리는 것과는 전혀 다릅니다.
Google은 이제 매우 성숙한 웹 기술인 링크 분석에 매우 능숙합니다. 따라서 PageRank가 유기적 SERP의 순위를 매기는 데 계속 사용될 가능성이 높습니다.
Bill Slawski가 지적한 또 다른 추세는 뉴스 및 기타 단기 검색 결과 유형이었습니다.
Google은 실시간 결과(예: Twitter)나 적시성이 매우 중요한 뉴스 결과와 같이 적시성이 더 중요한 페이지에 대해서는 PageRank에 덜 의존한다고 말했습니다.
실제로 검색 결과에 나오는 뉴스 중 백링크를 충분히 축적할 수 없을 정도로 적은 양의 뉴스가 검색됩니다. 따라서 Google은 뉴스를 다룰 때 백링크를 다른 순위 요소로 대체하기 위해 노력해 왔으며 앞으로도 계속 노력할 것입니다.
그러나 현재 뉴스 순위는 게시자의 틈새 권위성에 의해 크게 결정되며 우리는 여전히 권위성을 백링크로 읽습니다.
"신뢰성 신호는 가장 신뢰할 수 있는 소스에서 제공되는 고품질 정보의 우선순위를 정하는 데 도움이 됩니다. 이를 위해 Google 시스템은 검색 평가자의 피드백을 기반으로 특정 주제에 대한 전문성, 권위성, 신뢰성을 보여주는 페이지를 결정하는 데 도움이 되는 신호를 식별하도록 설계되었습니다.. 이러한 신호에는 다른 사람들이 유사한 검색어에 대한 출처를 중요하게 생각하는지 또는 해당 주제에 대한 다른 유명 웹사이트가 해당 기사에 대한 링크를 제공하는지 여부가 포함될 수 있습니다."
마지막으로, 스폰서 및 사용자 생성 백링크를 식별하고 팔로우하지 않은 다른 링크와 구별할 수 있도록 Google이 기울인 노력에 상당히 놀랐습니다.
모든 백링크를 무시해야 한다면 왜 백링크를 서로 구분해야 합니까? 특히 John Muller는 나중에 Google이 이러한 유형의 링크를 다르게 처리하려고 시도할 수도 있다고 제안했습니다.
여기서 가장 엉뚱한 추측은 어쩌면 Google이 광고와 사용자 생성 링크가 긍정적인 순위 신호가 될 수 있는지 여부를 검증하고 있다는 것입니다.
결국, 인기 있는 플랫폼에 광고하려면 막대한 예산이 필요하며, 막대한 예산은 크고 인기 있는 브랜드의 속성입니다.
댓글 스팸 패러다임 밖에서 고려될 때 사용자 생성 콘텐츠는 실제 고객이 실제 보증을 제공하는 것에 관한 것입니다.
그러나 제가 만난 전문가들은 그것이 가능하다고 믿지 않았습니다.

Google이 스폰서 링크를 긍정적인 신호로 간주할지는 의문입니다.
여기서 아이디어는 다양한 유형의 링크를 구별함으로써 Google이 엔터티 구축 목적으로 따라야 할 nofollow 링크 중 어떤 링크를 따라야 하는지 파악하려고 시도하는 것 같습니다.

Google은 웹사이트의 사용자 생성 콘텐츠나 스폰서 콘텐츠에 대해 아무런 문제가 없지만 둘 다 역사적으로 페이지 순위를 조작하는 방법으로 사용되어 왔습니다. 따라서 웹마스터는 nofollow를 사용하는 다른 이유 중에서 이러한 링크에 nofollow 속성을 배치하는 것이 좋습니다. 그러나 nofollowed 링크는 여전히 항목 인식과 같은 작업에 있어서 Google에 도움이 될 수 있으므로 이전에 다음과 같이 언급했습니다. 이것을 더 많은 제안으로 취급할 수 있으며 robots.txt 허용 금지 규칙과 같은 지시문이 귀하의 사이트에 있을 수는 없습니다. John Mueller의 진술은 다음과 같습니다..” 이는 Google이 nofollow를 제안으로 처리하는 경우를 의미할 수 있습니다. 가정적으로, Google 시스템은 ugc로 표시되고 후원받는 링크 유형에서 수집된 통찰력을 기반으로 어떤 nofollowed 링크를 따라갈 수 있는지 학습할 수 있습니다. 다시 말하지만, 이는 사이트 순위에 큰 영향을 미치지 않아야 합니다. 그러나 이론적으로는 링크되는 사이트에도 영향을 미칠 수 있습니다.
Google의 현재 검색 알고리즘에서 백링크의 역할을 명확히 할 수 있었으면 좋겠습니다. 기사를 조사하면서 발견한 일부 데이터는 나에게도 놀라운 내용이었습니다. 그래서 저는 댓글에서 여러분의 토론에 참여하기를 기대하고 있습니다.
아직 답변하지 못한 질문이 있나요? PageRank의 미래에 대해 갖고 있는 아이디어가 있습니까?






