101081
•
20 分で読めます
•


PageRankアルゴリズム (略して PR) は、90 年代後半にスタンフォード大学のラリー ペイジとサーゲイ ブリンによって開発された、Web ページをランク付けするためのシステムです。 PageRank は実際には、Page と Brin が Google 検索エンジンを作成した基礎でした。
それから長い年月が経ち、当然のことながら、Google のランキング アルゴリズムははるかに複雑になりました。それらは依然として PageRank に基づいていますか? PageRank は正確にランキングにどのような影響を及ぼしますか。ランキングが下がった理由の 1 つとして PageRank が考えられますか。また、SEO は今後どのようなことに備える必要がありますか?ここで、全体像を明確にするために、PageRank に関するすべての事実と謎を見つけて要約します。まあ、できる限り。
上で述べたように、ブリンとペイジは大学の研究プロジェクトで、Web ページの権威を推定するシステムを発明しようとしました。彼らは、ページに与えられる信頼の投票として機能するリンク上にそのシステムを構築することに決めました。そのメカニズムのロジックによれば、ページにリンクする外部リソースが増えるほど、ページに含まれるユーザーにとって価値のある情報が増えます。また、PageRank (着信リンクの量と質に基づいて計算される 0 から 10 までのスコア) は、インターネット上のページの相対的な権威を示しました。
PageRank がどのように機能するかを見てみましょう。あるページ (A) から別のページ (B) への各リンクは、いわゆる投票を行います。その重みは、ページ A にリンクしているすべてのページの合計の重みによって異なります。そして、計算するまでは、それらの重みを知ることはできません。したがって、プロセスはサイクルで実行されます。
元の PageRank の数式は次のとおりです。
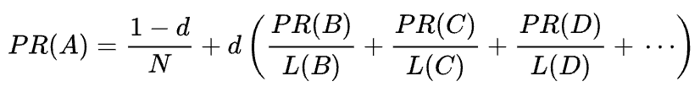
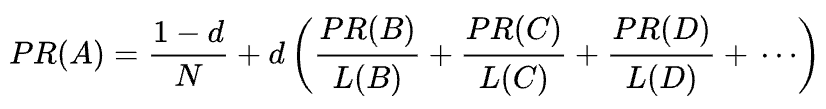
ここで、 A 、 B 、 C 、およびDはいくつかのページ、 Lはそれぞれのページから発信されるリンクの数、 Nはコレクション (つまりインターネット上) 内のページの総数です。
dについては、 dはいわゆる減衰率です。 PageRank がランダムにページにアクセスしてリンクをクリックするユーザーの行動をシミュレートして計算されることを考慮して、この減衰d係数をユーザーが飽きてページから離れる確率として適用します。
式からわかるように、ページを指しているページがない場合、その PR はゼロではありませんが、
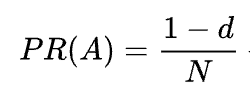
ユーザーが他のページからではなく、たとえばブックマークからこのページにアクセスする可能性があるためです。
当初、PageRank スコアは Google ツールバーに公開されており、各ページには 0 から 10 までのスコアがあり、おそらく対数スケールで表示されていました。
当時の Google のランキング アルゴリズムは非常にシンプルでした。SERP でページが上位にランクされるために必要なのは、高い PR とキーワード密度の 2 つだけでした。その結果、Web ページにはキーワードが詰め込まれ、Web サイト所有者はスパム バックリンクを人為的に増やすことで PageRank を操作し始めました。それは簡単でした。リンク ファームとリンク販売は、Web サイト所有者に「救いの手」を提供するために存在していました。
Googleはリンクスパムと戦うことを決定した。 2003年、Googleはリンク操作を理由に広告ネットワーク会社SearchKingのWebサイトに罰則を科した。 SearchKingはGoogleを訴えたが、Googleが勝訴した。これは Google がリンク操作をすべての人に制限しようとした方法でしたが、何も起こりませんでした。リンクファームは地下に潜り、その量は大幅に増加しました。
さらに、ブログへのスパムコメントも急増しました。ボットは、たとえば WordPress ブログのコメントを攻撃し、 「魔法の薬を買うにはここをクリックしてください」という膨大な数のコメントを残しました。コメントでのスパムや PR 操作を防ぐために、Google は 2005 年にnofollowタグを導入しました。そしてまたしても、Google がリンク操作戦争で成功を収めようとしていたことが、歪んだ方法で実装されました。人々はnofollowタグを使用して、PageRank を必要なページに人為的に集め始めました。この戦術は、PageRank スカルプティングとして知られるようになりました。
PR スカルプティングを防ぐために、Google は PageRank のフロー方法を変更しました。以前は、ページにnofollow リンクとdofollowリンクの両方がある場合、そのページのすべての PR ボリュームが、 dofollowリンクでリンクされている他のページに渡されていました。 2009 年、Google はページの PR をページに含まれるすべてのリンクに均等に分割し始めましたが、 dofollowリンクに与えられたシェアのみを渡しました。


PageRank のスカルプティングを終えた後も、Google はリンクスパム戦争を止めず、その結果、PageRank スコアを一般の人々の目から奪い始めました。まず、Google は、PR スコアが表示される Google ツールバーなしで新しい Chrome ブラウザを起動しました。その後、Google Search Console での PR スコアの報告を中止しました。その後、Firefox ブラウザは Google ツールバーのサポートを停止しました。 2013 年に Internet Explorer 向けに PageRank が最後に更新され、2016 年に Google はツールバーの一般公開を正式に終了しました。


Google がリンク スキームと戦うために使用したもう 1 つの方法は、疑わしいバックリンク プロファイルを持つ Web サイトのランクを下げるペンギン アップデートでした。 2012 年に公開されたペンギンは、Google のリアルタイム アルゴリズムの一部ではなく、検索結果に時々更新され再適用される「フィルター」でした。 Web サイトがペンギンによってペナルティを受けた場合、SEO はリンク プロファイルを注意深く確認して有害なリンクを削除するか、否認リスト (PageRank を計算する際にどの受信リンクを無視するかを Google に指示するために当時導入された機能) に追加する必要がありました。この方法でリンク プロファイルを監査した後、SEO はペンギン アルゴリズムがデータを再計算するまで半年ほど待たなければなりませんでした。
2016 年、Google はペンギンをその中核となるランキング アルゴリズムの一部に組み込みました。それ以来、リアルタイムで動作し、アルゴリズム的にスパムをよりうまく処理できるようになりました。
同時に、Google はリンクの量ではなく質の向上に取り組み、 リンク スキームに対する品質ガイドラインにそれを明記しました。
さて、PageRank の過去は終わりです。いま何が起きているのですか?
2019年に遡ると、 元Google従業員は、元のPageRankアルゴリズムは2006年以来使用されておらず、インターネットの成長に伴い、リソース集約度の低い別のアルゴリズムに置き換えられたと述べた。 2006 年に Google がWeb リンク グラフの特許で、距離を使用したページのランキングの作成に関する新しい特許を申請したことから、これはおそらく真実かもしれません。
はい、そうです。 2000 年代初頭と同じ PageRank ではありませんが、Google はリンクオーソリティに大きく依存し続けています。たとえば、元 Google 従業員のAndrey Lipattsev 氏は 2016 年にこれについて言及しました。Googleの Q&A ハングアウトで、あるユーザーが彼に、Google が使用する主なランキング シグナルは何なのかと尋ねました。アンドレイの答えは非常に単純でした。

それらが何であるかを教えてください。それはあなたのサイトを指すコンテンツとリンクです。
2020 年、ジョン ミュラーは次のことを再度確認しました。

はい、他の多くのシグナルの中で、PageRank を内部的に使用しています。これは元の論文と全く同じではなく、多くの癖があり (否認リンク、無視リンクなど)、また、より強力になる可能性のある他のシグナルを多数使用しています。
ご覧のとおり、PageRank は今も生きており、Web 上のページをランク付けするときに Google によって積極的に使用されています。
興味深いのは、Google の従業員が、他にもたくさんのGoogle ランキング要素があることを私たちに思い出させ続けていることです。しかし、私たちはこれを少し割り引いて考えます。 Google がリンクスパム対策にどれだけの労力を費やしたかを考えると、SEO 担当者の注意を操作の脆弱な要素 (バックリンクなど) から切り替え、その注意を無害で優れたものに向けることは Google の利益になる可能性があります。しかし、SEO は行間を読むのが得意なので、PageRank を強力なランキングシグナルと考え続け、あらゆる方法でバックリンクを増やします。彼らは、一昔前と同じように、今でも PBN を使用し、段階的なリンク構築を実践し、リンクを購入するなどしています。 PageRank が存続する限り、リンク スパムも存続します。私たちはそれを推奨しませんが、それが SEO の現実であり、それを理解する必要があります。
さて、現在の PageRank は 20 年前の PageRank ではないということはおわかりでしょう。
PR の主要な近代化の 1 つは、2012 年に上記で簡単に説明したランダム サーファー モデルからReasonable Surferモデルに移行したことでした。Reasonable Surfer は、ユーザーがページ上で無秩序に行動せず、ページ上で興味のあるリンクのみをクリックすることを前提としています。一瞬。たとえば、ブログ記事を読んでいると、フッターにある利用規約のリンクよりも、記事のコンテンツにあるリンクをクリックする可能性が高くなります。
さらに、Reasonable Surfer は、リンクの魅力を評価する際に、他のさまざまな要素を使用できる可能性があります。これらすべての要素は Bill Slawski 氏の記事で注意深く検討されていますが、ここでは SEO 担当者が頻繁に議論する 2 つの要素に焦点を当てたいと思います。これらはリンクの位置とページのトラフィックです。これらの要因について何が言えるでしょうか?
リンクは、ページ上のどこにでも配置できます。コンテンツ、ナビゲーション メニュー、作成者の略歴、フッター、および実際にはページに含まれるあらゆる構造要素に配置できます。また、リンクの場所が異なるとリンクの値に影響します。ジョン・ミューラー氏もこれを認め、メインコンテンツ内に配置されたリンクは他のすべてのリンクよりも重要であると述べた。
これは、主要なコンテンツが含まれるページの領域であり、メニュー、サイドバー、フッター、ヘッダーではなく、このページが実際に扱っているコンテンツです。そのため、私たちはそれを考慮し、実際に試みます。それらのリンクを使用します。
そのため、フッター リンクとナビゲーション リンクは、より少ない重みを渡すと言われています。そしてこの事実は、Google の広報担当者だけでなく、実際の事例によっても確認されることがあります。
ブライトンSEOのMartin Hayman氏が紹介した最近の事例では、Martin氏はナビゲーションメニューにすでに持っていたリンクをページのメインコンテンツに追加しました。その結果、これらのカテゴリ ページとそのリンク先のページのトラフィックが 25% 増加しました。
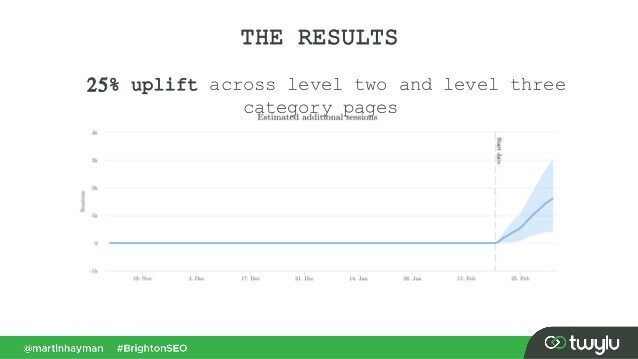
この実験は、コンテンツ リンクが他のどのリンクよりも大きな重みを渡すことを証明しています。
著者の略歴内のリンクに関して、SEO は、略歴のリンクにはある程度の価値はあるものの、たとえばコンテンツのリンクよりも価値が低いと想定しています。ここではあまり証拠がありませんが、Google がバックリンクを求めて過剰なゲスト ブログと積極的に戦っていたときにマット カッツ氏が言ったこと以外には証拠がありません。
John Mueller 氏は、 Search Console Central ハングアウトの 1 つでリンク ジュースを渡すという観点から、Google がトラフィックとユーザーの行動をどのように扱うかを明らかにしました。ユーザーは、Googleがリンクの品質を評価する際にクリック確率とリンククリック数を考慮しているかどうかをミューラー氏に尋ねた。モラー氏の回答から得られた主なポイントは次のとおりです。
Google は、リンクの品質を評価する際に、リンクのクリック数やクリック確率を考慮しません。
Google は、リンクは参照などのコンテンツに追加されることが多く、ユーザーは見つけたすべてのリンクをクリックすることを期待されていないことを理解しています。
それでも、いつものように、SEO 担当者は Google の言うことすべてを盲目的に信じる価値があるかどうかを疑っており、実験を続けています。そこで、Ahrefs のチームは、SERP 上のページの位置が、トラフィックの多いページからのバックリンクの数に関係しているかどうかを確認する調査を実施しました。研究により、相関関係はほとんどないことが明らかになりました。さらに、上位にランクされた一部のページには、トラフィックの多いページからのバックリンクがまったくないことが判明しました。
この研究は、ジョン・ミューラー氏の言葉と同じ方向性を私たちに示しています。SERP で上位を獲得するために、ページへのトラフィックを生み出すバックリンクを構築する必要はありません。一方で、余分なトラフィックが Web サイトに害を及ぼすことはありません。ここでの唯一のメッセージは、トラフィックの多いバックリンクは Google のランキングに影響を与えないようだということです。
覚えているとおり、Google はリンク スパムに対抗する方法として 2005 年にnofollowタグを導入しました。今日何か変化はありましたか?実はそうです。
まず、Google は最近さらに 2 種類のnofollow属性を導入しました。その前に、Googleは、ブログのコメントであろうと有料広告であろうと、PageRankの計算に参加したくないすべてのバックリンクをnofollowとしてマークすることを提案しました。現在、Google は有料リンクとアフィリエイト リンクにはrel="スポンサー"を使用し、ユーザー作成コンテンツにはrel="ugc" を使用することを推奨しています。

興味深いのは、これらの新しいタグが (少なくともまだ) 必須ではないことです。Google は、すべてのrel=”nofollow” をrel=”owned”およびrel=”ugc”に手動で変更する必要がないことを指摘しています。これら 2 つの新しい属性は、通常のnofollowタグと同じように機能するようになりました。
第二に、Googleは現在、 nofollowタグと新しいタグであるspopondおよびugcは、ページのインデックス作成時にディレクティブではなくヒントとして扱われると述べています。
受信リンクに加えて、送信リンク、つまりあなたのページから他のページを指すリンクもあります。
多くの SEO は、発信リンクがランキングに影響を与える可能性があると信じていますが、この思い込みはSEO の迷信として扱われてきました。しかし、この点に関しては、注目すべき興味深い研究が 1 つあります。
Reboot Online は 2015 年に実験を実施し、2020 年に再実行しました。彼らは、権威の高いページへの発信リンクの存在が、SERP 上のページの位置に影響を与えるかどうかを解明したいと考えていました。彼らは 300 ワードの記事を含む 10 の Web サイトを作成し、すべてが存在しないキーワードである Phylandocic に最適化されました。 5 つの Web サイトには発信リンクがまったくなく、5 つの Web サイトには権威あるリソースへの発信リンクが含まれていました。その結果、信頼できる発信リンクを持つ Web サイトが最上位にランクされるようになり、リンクをまったく持たない Web サイトは最下位になりました。
.png)
一方で、この調査結果から、発信リンクがページの位置に影響を与えることがわかります。一方、調査の検索語はまったく新しいものであり、Web サイトのコンテンツは医学や薬物をテーマとしています。したがって、クエリが YMYL として分類された可能性が高くなります。そして Google は、 YMYL ウェブサイトにおける EAT の重要性を何度も述べてきました。したがって、アウトリンクは、ページに事実に正確なコンテンツがあることを証明する EAT シグナルとして扱われた可能性があります。
通常のクエリ ( YMYLではない) に関しては、発信リンクはユーザーにとって有益であるため、コンテンツから外部ソースにリンクすることを恐れる必要はない、と John Mueller は何度も述べています。
さらに、発信リンクは、Web をスパムからフィルタリングするときにGoogle AI によって考慮される可能性があるため、SEO にとっても有益である可能性があります。なぜなら、スパムページには、発信リンクがあったとしてもほとんどない傾向があるからです。同じドメイン内のページにリンクしているか (SEO を考慮している場合)、有料リンクのみが含まれています。したがって、信頼できるリソースにリンクすると、そのページがスパムではないことを Google に示すことになります。
かつて、Google は発信リンクが多すぎると手動ペナルティを与える可能性があるという意見がありましたが、ジョン・ミューラー氏は、発信リンクが明らかに何らかのリンク交換スキームの一部であり、さらにウェブサイトが一般的に質の悪い。 Google が「明白」で何を意味するかは実際には謎であるため、常識、高品質のコンテンツ、および基本的な SEOを念頭に置いてください。
PageRank が存在する限り、SEO はそれを操作する新しい方法を模索するでしょう。
2012 年当時、Google はリンク操作やスパムに対して手動による措置をリリースする可能性が高かったです。しかし現在、Google は十分に訓練されたスパム対策アルゴリズムを使用して、Web サイト全体全体のランクを下げるのではなく、PageRank を計算する際に特定のスパムリンクを無視することができます。ジョン・ミューラーが言ったように、
長年にわたって収集されたランダムなリンクは必ずしも有害ではありません。私たちも長い間それらを見てきたので、昔からの奇妙な Web 落書きはすべて無視できます。
これは、バックリンク プロファイルが競合他社によって侵害された場合のネガティブ SEOにも当てはまります。
一般に、私たちはこれらのことを自動的に考慮し、それらが起こっているのを見たときは自動的に無視しようとします。ほとんどの場合、これはかなりうまく機能すると思います。この点に関して実際に問題を抱えている人はほとんどいません。それで、ほとんどうまくいっていると思います。これらのリンクの否認に関しては、これらが Web サイトに表示されるだけの通常のスパムリンクである場合は、あまり心配する必要はないと思います。おそらく私たちはそれを自分たちで考え出したのでしょう。
ただし、何も心配する必要がないわけではありません。ウェブサイトのバックリンクがあまりにも頻繁に無視される場合、手動による対応が必要になる可能性が高くなります。マリー・ヘインズ氏は、2021 年のリンク管理に関するアドバイスで次のように述べています。

手動による対処は、それ以外はまともなサイトに、そのサイトを指す不自然なリンクが大規模であり、Google のアルゴリズムがそれらを無視することに抵抗がある場合に備えて確保されています。
どのリンクが問題の原因となっているかを特定するには、 バックリンクの品質を確認する方法に関するこのガイドをお読みください。つまり、 SEO SpyGlassのようなバックリンク チェッカーを使用できます。ツールで、 [バックリンク プロファイル] > [ペナルティ リスク]セクションに移動します。高リスクおよび中リスクのバックリンクに注意してください。
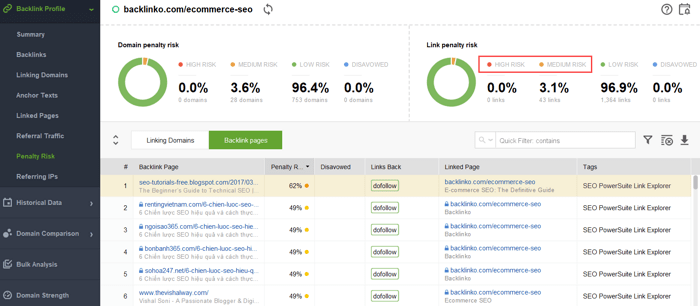
特定のリンクが有害として報告される理由をさらに調査するには、 「ペナルティ リスク」列の「 i」記号をクリックします。ここでは、ツールがリンクを不正であると判断した理由を確認し、リンクを否認するかどうかを決定します。
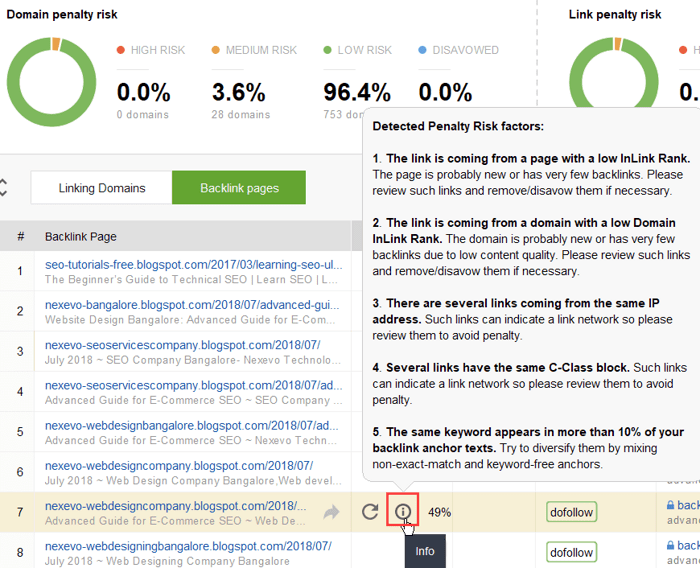
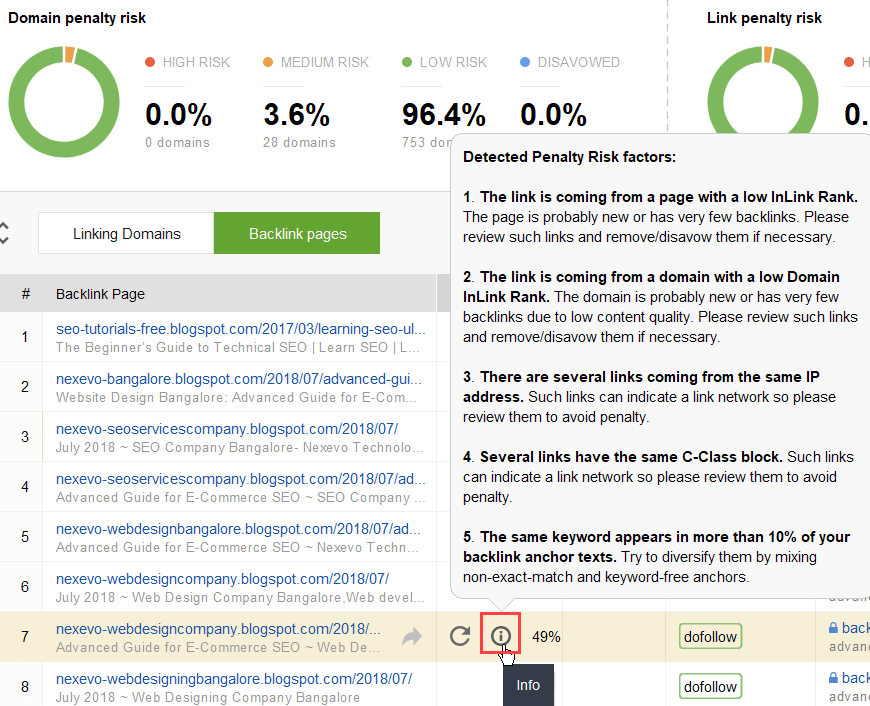
リンクのグループのリンクを否認することにした場合は、それらを右クリックし、 [バックリンクの否認]オプションを選択します。
除外するリンクのリストを作成したら、SEO SpyGlass から否認ファイルをエクスポートし、GSC 経由で Google に送信できます。
PageRank について言えば、内部リンクについて触れずにはいられません。受信する PageRank は私たちには制御できないものですが、PR を Web サイトのページ全体に広める方法は完全に制御できます。
Googleも内部リンクの重要性を何度も述べています。 John Mueller 氏は、最新のSearch Console Central ハングアウトの 1 つで、この点をもう一度強調しました。ユーザーから、いくつかの Web ページをより強力にする方法について質問されました。そしてジョン・ミュラー氏は次のように述べた。
...内部リンクにご協力いただけます。したがって、Web サイト内で、さらに強調表示したいページを実際に強調表示し、それらのページが内部的に適切にリンクされていることを確認できます。また、それほど重要ではないと思われるページについては、内部リンクを少し減らすようにしてください。
内部リンクには大きな意味があります。これは、受信した PageRank を Web サイト上の異なるページ間で共有するのに役立ち、パフォーマンスの低いページを強化し、Web サイト全体を強化します。
内部リンクへのアプローチに関して、SEO にはさまざまな理論があります。一般的なアプローチの 1 つは、 Web サイトのクリック深さに関連するものです。この考え方は、Web サイト上のすべてのページがホームページから最大 3 クリックの距離になければならないことを示しています。 Google も、 浅い Web サイト構造の重要性を何度も強調していますが、実際には、これは大小のすべての Web サイトにとって到達不可能であるようです。
もう 1 つのアプローチは、集中型および分散型の内部リンクの概念に基づいています。 ケビン・インディグは次のように説明しています。

一元化されたサイトには、1 つの主要なページを指す単一のユーザー フローとファネルがあります。分散型の内部リンクを備えたサイトには、複数のコンバージョン タッチポイントやサインアップ用のさまざまな形式があります。
一元的な内部リンクの場合、コンバージョン ページの小さなグループまたは 1 つのページがあり、これを強力にする必要があります。分散型内部リンクを適用する場合、Web サイトのすべてのページが同等に強力で、すべてのページがクエリに対してランク付けされるように同等の PageRank を持つようにしたいと考えています。
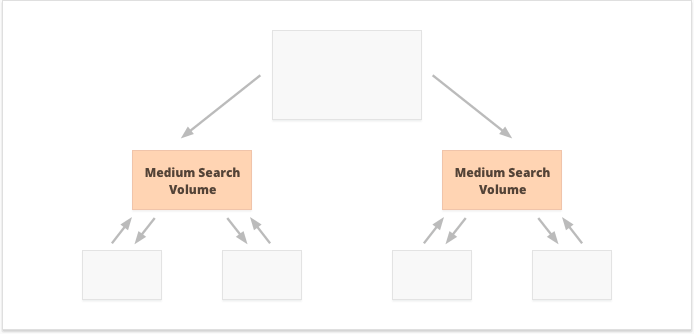
どのオプションが良いでしょうか?それはすべて、ウェブサイトとビジネスのニッチな特性、およびターゲットとするキーワードによって異なります。たとえば、一元化された内部リンクは、非常に強力なページの狭いセットが得られるため、検索ボリュームが高いおよび中程度のキーワードに適しています。
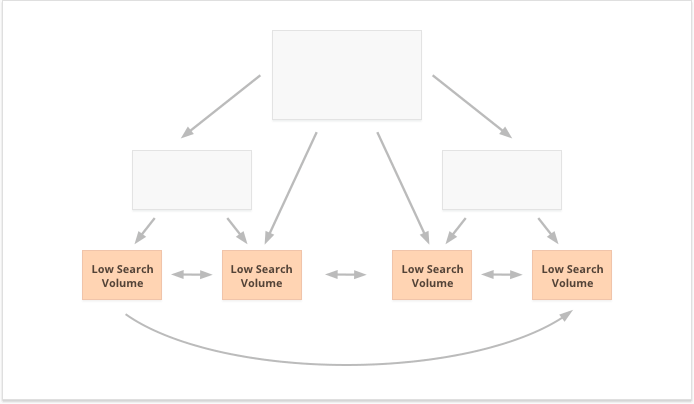
逆に、検索ボリュームの少ないロングテールキーワードは、多数の Web サイトページに PR が均等に分散されるため、分散型の内部リンクに適しています。
内部リンクを成功させるもう 1 つの側面は、ページ上の受信リンクと送信リンクのバランスです。これに関して、多くの SEO は実際には逆 PageRank であるCheiRank (CR) を使用しています。ただし、PageRank が受け取る電力であるのに対し、CheiRank は与えられるリンク電力です。ページの PR と CR を計算すると、どのページにリンク異常があるか、つまり、ページが多くの PageRank を受け取ったものの、少し遅れた場合やその逆の場合がわかります。
ここでの興味深い実験は、Kevin Indig によるリンク異常の平坦化です。 Web サイトのすべてのページで受信および送信の PageRank のバランスが取れていることを確認するだけで、非常に印象的な結果が得られました。ここの赤い矢印は、異常が修正された時刻を示しています。
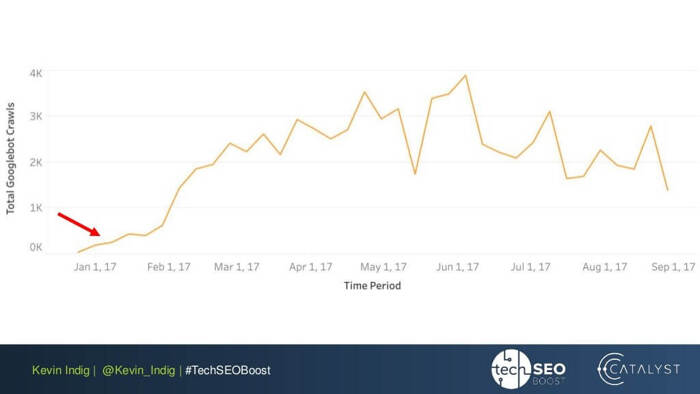
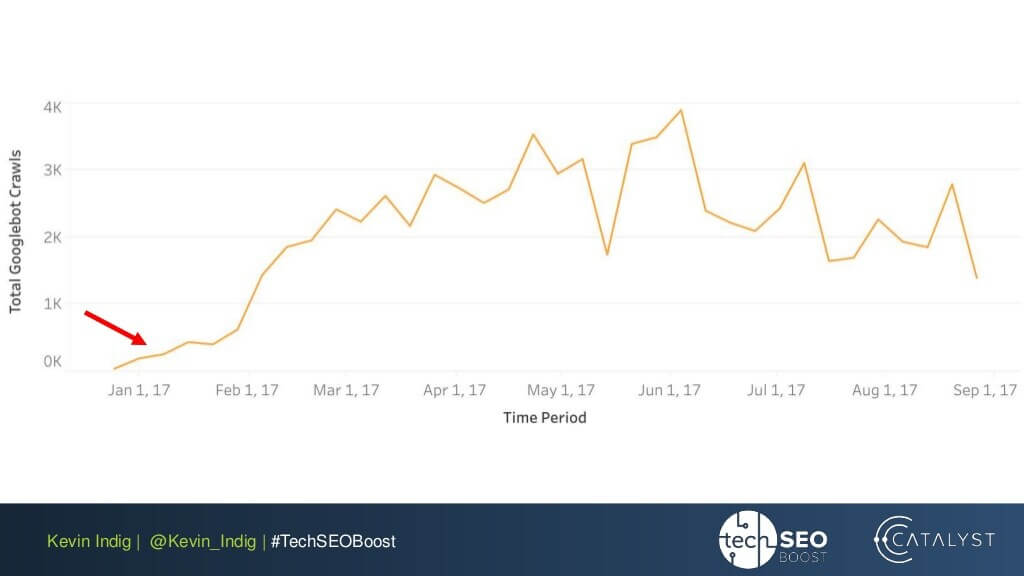
PageRank フローに悪影響を与える可能性があるのは、リンクの異常だけではありません。技術的な問題に巻き込まれないように注意してください。技術的な問題が発生すると、苦労して獲得した PR が台無しになる可能性があります。
孤立したページ。孤立したページは Web サイト上の他のページにリンクされていないため、アイドル状態にあり、リンク ジュースを受け取りません。 Google はそれらを確認することができず、それらが実際に存在することを知りません。
リダイレクトチェーン。 Google は リダイレクトが PR を 100% 通過するようになったと言っていますが、依然として長いリダイレクト チェーンを避けることが推奨されています。まず、とにかくクロール バジェットを食い尽くしてしまいます。第二に、Google の言うことすべてを盲目的に信じることはできないことを私たちは知っています。
解析できない JavaScript 内のリンク。 Google がそれらを読み取ることができないため、PageRank は渡されません。
404 リンク。 404 リンクはどこにも行きません。同じように、PageRank もどこにも行きません。
重要ではないページへのリンク。もちろん、ページにリンクをまったく持たないままにすることはできませんが、ページは同じように作成されるわけではありません。一部のページの重要性が低い場合、そのページのリンク プロファイルの最適化に多大な労力を費やすのは合理的ではありません。
ページが遠すぎます。ページが Web サイトの奥深くに配置されている場合、PR がほとんど行われないか、まったく PR されない可能性があります。 Google がそれを見つけてインデックスに登録できない可能性があるためです。
Web サイトにこれらの PageRank の危険がないことを確認するには、 WebSite Auditorを使用して Web サイトを監査できます。このツールには、 [サイト構造] > [サイト監査]セクション内に包括的なモジュール セットがあり、Web サイトの全体的な最適化をチェックでき、もちろん、長いリダイレクトなどのリンク関連の問題をすべて見つけて修正できます。
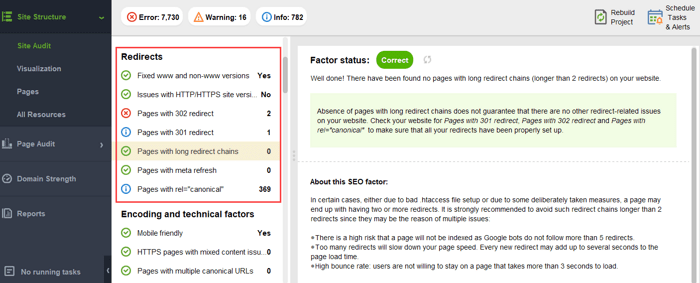
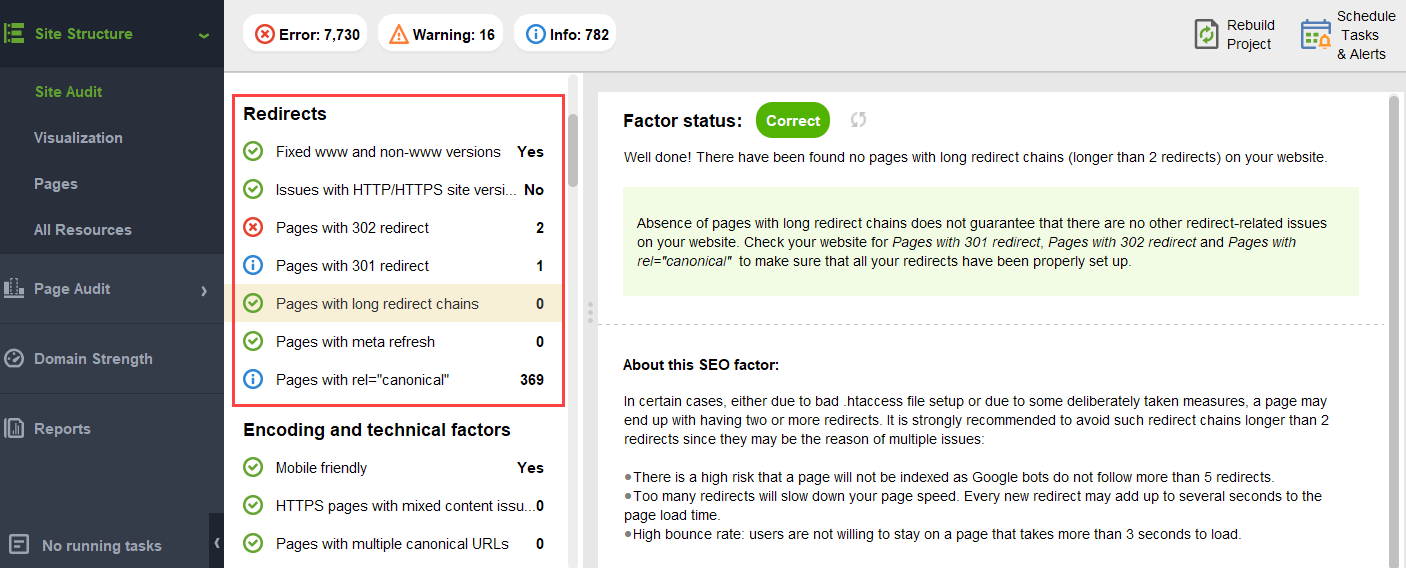
壊れたリンク:
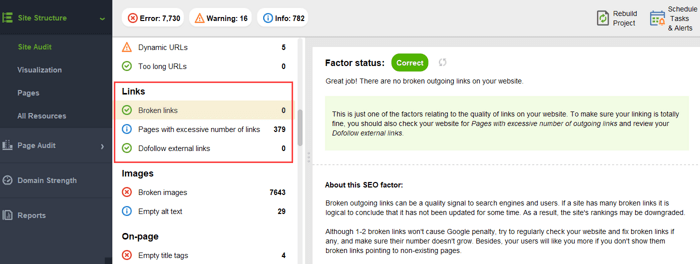
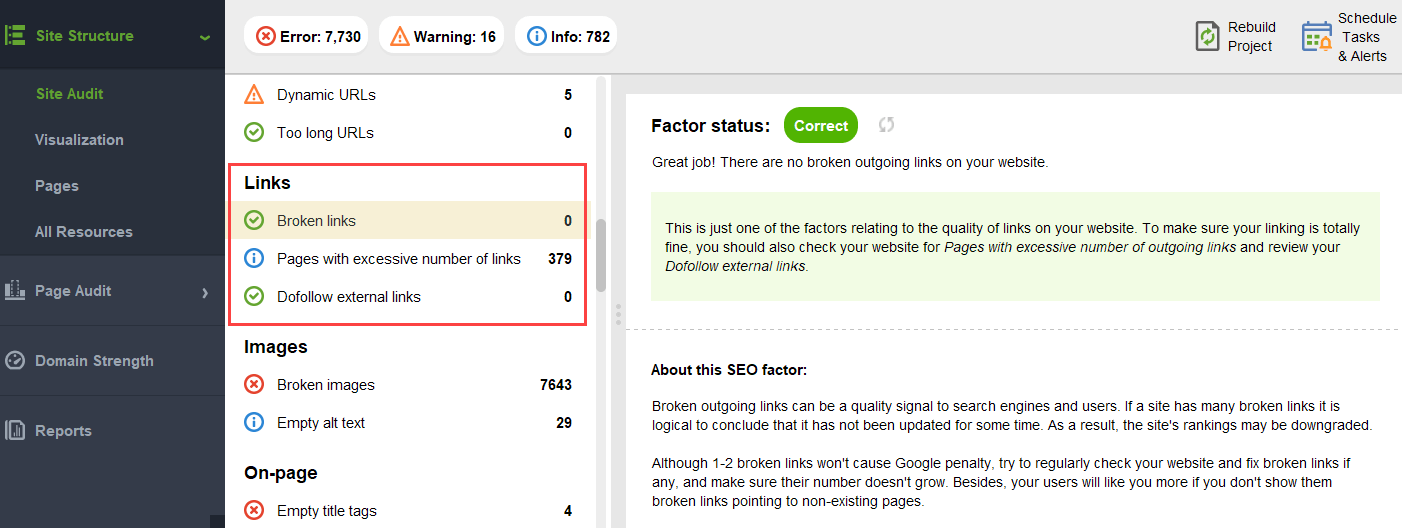
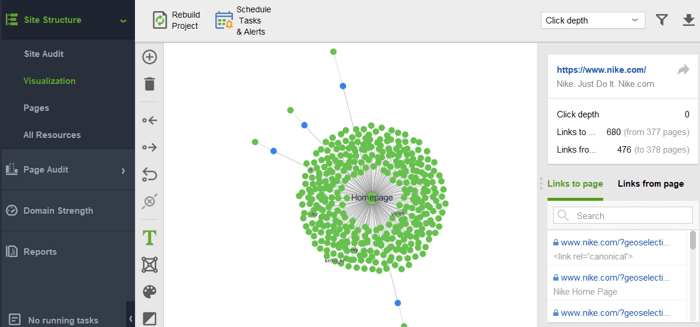
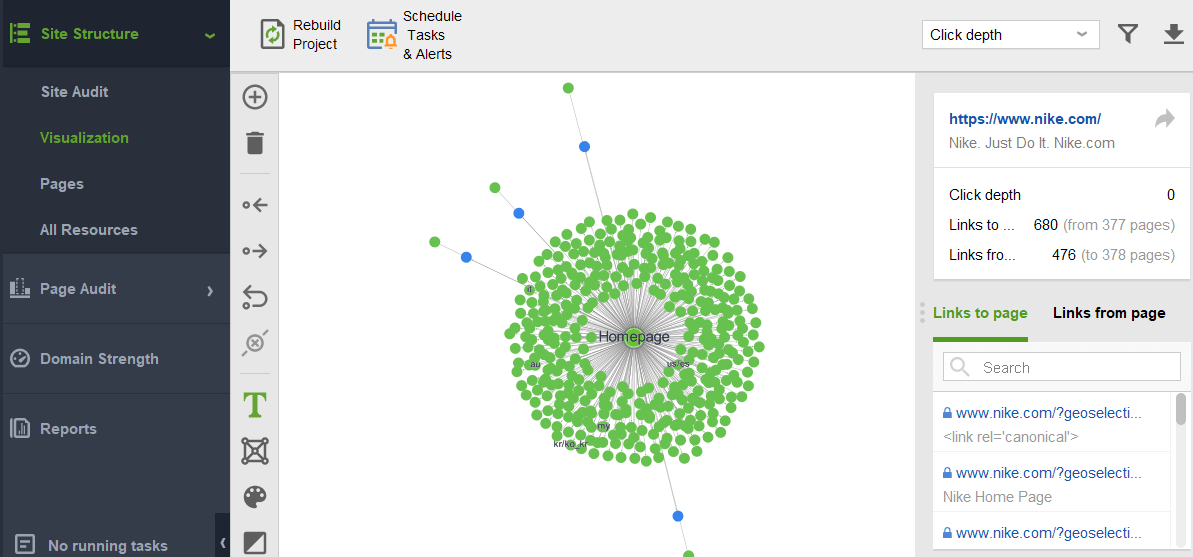
サイトに孤立したページや離れすぎたページがないか確認するには、 [サイト構造] > [視覚化]に切り替えます。
今年、PageRank は 23 歳になりました。そして、今日の読者の何人かよりも古いと思います:) しかし、PageRank は将来どうなるでしょうか?いつか完全に消滅してしまうのでしょうか?
アルゴリズムにバックリンクを使用していない人気の検索エンジンについて考えようとしたとき、私が思いつく唯一のアイデアは、 2014 年の Yandex の実験です。検索エンジンは、アルゴリズムからバックリンクを削除することで、最終的にリンクスパマーによる操作を阻止し、彼らの努力を質の高いウェブサイト作成に向けることができるかもしれないと発表した。
それは、代替のランキング要素に移行するための純粋な取り組みであった可能性もあれば、リンク スパムを削除するよう大衆を説得するための単なる試みであった可能性もあります。しかし、いずれにせよ、発表からわずか 1 年で、Yandex はバックリンク要素がシステムに戻ったことを確認しました。
しかし、なぜバックリンクは検索エンジンにとって不可欠なのでしょうか?
ユーザーの行動やBERT の調整など、表示を開始した後に検索結果を再配置するためのデータポイントは他にも無数にありますが、バックリンクは依然として初期の SERP を形成するために必要な最も信頼できる信頼性の基準の 1 つです。ここでの唯一の競争相手はおそらくエンティティです。
PageRank の将来について尋ねられた Bill Slawski 氏は次のように述べています。
.png)
Google は、機械学習と事実抽出を研究し、ビジネス エンティティの主要な値のペアを理解しています。これは、セマンティック検索への動き、構造化データとデータ品質のより良い使用を意味します。
それでも、Google は、何十年も開発に投資してきたものを放棄するわけにはいきません。
Google はリンク分析に非常に優れており、これは現在非常に成熟した Web テクノロジーです。そのため、オーガニック SERP のランク付けに PageRank が引き続き使用される可能性は十分にあります。
Bill Slawski 氏が指摘したもう 1 つの傾向は、ニュースやその他の短期間の検索結果です。
Google は、リアルタイムの結果 (Twitter など) やニュースの結果など、適時性がより重要なページでは、PageRank への依存度を低くしており、適時性が非常に重要であると述べています。
実際、検索結果にニュースが表示されるのは、十分なバックリンクを蓄積するには少なすぎます。そのため、Google はニュースを扱う際に、バックリンクを他のランキング要素に置き換えることにこれまでも取り組んできましたし、今後も取り組んでいく可能性があります。
ただし、現時点では、ニュースのランキングは発行者のニッチな権威によって大きく左右されており、私たちは依然として権威をバックリンクとして捉えています。
「権威性シグナルは、利用可能な最も信頼できる情報源からの高品質な情報を優先するのに役立ちます。これを行うために、当社のシステムは、検索評価者からのフィードバックに基づいて、特定のトピックに関してどのページが専門知識、権威性、信頼性を証明しているかを判断するのに役立つシグナルを識別するように設計されています。これらのシグナルには、他の人が同様のクエリのソースを評価しているかどうか、またはその件に関する他の著名な Web サイトがその記事にリンクしているかどうかなどが含まれます。」
最後になりましたが、私は、スポンサー付きのバックリンクとユーザー生成のバックリンクを識別し、他の nofollow リンクと区別できるようにするために Google が行った努力にかなり驚きました。
これらすべてのバックリンクが無視されるのであれば、なぜバックリンクとバックリンクを区別する必要があるのでしょうか?特に John Muller 氏は、Google が今後、 こうした種類のリンクを別の方法で処理しようとする可能性があると示唆しています。
ここでの私の最も大胆な推測は、おそらく Google が、広告とユーザー生成のリンクが上位のランキングシグナルになるかどうかを検証しているのではないかということでした。
結局のところ、人気のあるプラットフォームでの広告には莫大な予算が必要であり、巨大な予算は大規模で人気のあるブランドの特質です。
ユーザー生成コンテンツは、コメント スパム パラダイムの外側で考慮される場合、実際の顧客が実際の生活での支持を表明するものです。
しかし、私が連絡を取った専門家は、それが可能であるとは信じていませんでした。

Google がスポンサーリンクを肯定的なシグナルとみなすとは思えません。
ここでのアイデアは、さまざまな種類のリンクを区別することによって、Google がエンティティ構築の目的で nofollow リンクのどれをたどるべきかを判断しようとするということのようです。

Google は、Web サイト上のユーザー生成コンテンツやスポンサー付きコンテンツについては問題ありませんが、どちらも歴史的にページランクを操作する方法として使用されてきました。そのため、ウェブマスターは、これらのリンクに nofollow 属性を配置することが推奨されます (nofollow を使用する他の理由の中でも特に)。ただし、nofollow リンクは依然として Google にとって役立つ可能性があるため (エンティティ認識など)、以前に次のように述べています。これは、自分のサイトにある robots.txt の不許可ルールのような指示ではなく、提案として扱うことができます。ジョン ミューラーの発言は次のとおりです。 」これは、Google が nofollow を提案として扱うケースを指している可能性があります。仮説として、UGC およびスポンサー付きとしてマークアップされたリンクの種類から収集された洞察に基づいて、Google のシステムがどの nofollowed リンクをたどるべきかを学習できる可能性があります。繰り返しになりますが、これはサイトのランキングに大きな影響を与えるものではありませんが、理論的にはリンクされているサイトにも影響を与える可能性があります。
Google の現在の検索アルゴリズムにおけるバックリンクの役割を明確にできたことを願っています。この記事を調査中に見つけたデータのいくつかは、私にとっても驚きでした。コメントでの議論に参加できることを楽しみにしています。
まだ答えられていない質問はありますか? PageRank の将来について何かアイデアはありますか?






