101081
•
Lectura de 20 minutos
•


El algoritmo PageRank (o PR para abreviar) es un sistema para clasificar páginas web desarrollado por Larry Page y Sergey Brin en la Universidad de Stanford a finales de los años 90. PageRank fue en realidad la base sobre la que Page y Brin crearon el motor de búsqueda de Google.
Han pasado muchos años desde entonces y, por supuesto, los algoritmos de clasificación de Google se han vuelto mucho más complicados. ¿Siguen basándose en PageRank? ¿Cómo influye exactamente el PageRank en la clasificación? ¿Podría ser una de las razones por las que su clasificación ha caído y para qué deberían prepararse los SEO en el futuro? Ahora vamos a encontrar y resumir todos los hechos y misterios en torno al PageRank para aclarar el panorama. Bueno, tanto como podamos.
Como se mencionó anteriormente, en su proyecto de investigación universitario, Brin y Page intentaron inventar un sistema para estimar la autoridad de las páginas web. Decidieron construir ese sistema sobre enlaces, que servían como votos de confianza otorgados a una página. Según la lógica de ese mecanismo, cuantos más recursos externos enlacen a una página, más información valiosa tendrá para los usuarios. Y el PageRank (una puntuación de 0 a 10 calculada en función de la cantidad y calidad de los enlaces entrantes) mostró la autoridad relativa de una página en Internet.
Echemos un vistazo a cómo funciona el PageRank. Cada enlace de una página (A) a otra (B) emite un llamado voto, cuyo peso depende del peso colectivo de todas las páginas que enlazan a la página A. Y no podemos saber su peso hasta que calculemos así que el proceso va en ciclos.
La fórmula matemática del PageRank original es la siguiente:
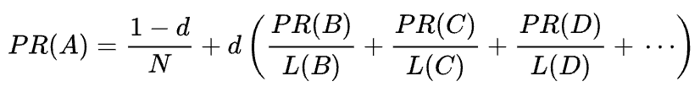
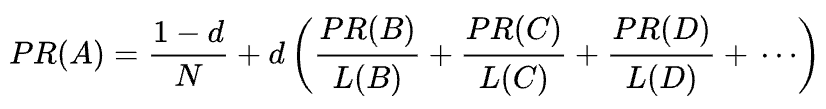
Donde A, B, C y D son algunas páginas, L es el número de enlaces que salen de cada una de ellas y N es el número total de páginas de la colección (es decir, en Internet).
En cuanto a d, d es el llamado factor de amortiguación. Teniendo en cuenta que el PageRank se calcula simulando el comportamiento de un usuario que accede aleatoriamente a una página y hace clic en enlaces, aplicamos este factor de amortiguación d como la probabilidad de que el usuario se aburra y abandone una página.
Como puede ver en la fórmula, si no hay páginas que apunten a la página, su PR no será cero sino
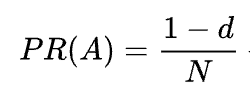
Ya que existe la probabilidad de que el usuario pueda llegar a esta página no desde otras páginas sino, por ejemplo, desde los marcadores.
Al principio, la puntuación de PageRank era visible públicamente en la barra de herramientas de Google y cada página tenía su puntuación de 0 a 10, probablemente en una escala logarítmica.
Los algoritmos de clasificación de Google de aquellos tiempos eran realmente simples: altas relaciones públicas y densidad de palabras clave eran las dos únicas cosas que una página necesitaba para tener una clasificación alta en un SERP. Como resultado, las páginas web se llenaron de palabras clave y los propietarios de sitios web comenzaron a manipular el PageRank mediante el crecimiento artificial de vínculos de retroceso spam. Eso fue fácil de hacer: las granjas de enlaces y la venta de enlaces estaban ahí para ayudar a los propietarios de sitios web.
Google decidió luchar contra el spam de enlaces. En 2003, Google penalizó el sitio web de la empresa de redes publicitarias SearchKing por manipulación de enlaces. SearchKing demandó a Google, pero Google ganó. Fue una forma en que Google intentó impedir que todos manipularan enlaces, sin embargo, no condujo a nada. Las granjas de enlaces simplemente pasaron a ser clandestinas y su cantidad se multiplicó enormemente.
Además, los comentarios spam en los blogs también se multiplicaron. Los bots atacaron los comentarios de cualquier blog de WordPress, por ejemplo, y dejaron enormes cantidades de comentarios de tipo “haga clic aquí para comprar píldoras mágicas”. Para evitar el spam y la manipulación de relaciones públicas en los comentarios, Google introdujo la etiqueta nofollow en 2005. Y una vez más, lo que Google pretendía convertir en un paso exitoso en la guerra de manipulación de enlaces se implementó de una manera retorcida. La gente empezó a utilizar etiquetas nofollow para canalizar artificialmente el PageRank a las páginas que necesitaban. Esta táctica se conoció como escultura de PageRank.
Para evitar la escultura de relaciones públicas, Google cambió la forma en que fluye el PageRank. Anteriormente, si una página tenía enlaces nofollow y dofollow, todo el volumen de relaciones públicas de la página se pasaba a otras páginas vinculadas con enlaces dofollow. En 2009, Google comenzó a dividir las relaciones públicas de una página en partes iguales entre todos los enlaces que tenía, pero pasando solo aquellas acciones que se otorgaban a los enlaces dofollow.


Una vez terminada la escultura del PageRank, Google no detuvo la guerra de spam de enlaces y, en consecuencia, comenzó a quitar la puntuación del PageRank de los ojos del público. Primero, Google lanzó el nuevo navegador Chrome sin la barra Google donde se mostraba la puntuación de relaciones públicas. Luego dejaron de informar la puntuación de relaciones públicas en Google Search Console. Luego, el navegador Firefox dejó de admitir la barra Google. En 2013, PageRank se actualizó para Internet Explorer por última vez y en 2016 Google cerró oficialmente la barra Google para el público.


Una forma más que utilizó Google para luchar contra los esquemas de vínculos fue la actualización de Penguin, que desclasificaba los sitios web con perfiles de vínculos de retroceso sospechosos. Lanzado en 2012, Penguin no pasó a formar parte del algoritmo en tiempo real de Google, sino que era más bien un "filtro" que se actualizaba y se reaplicaba a los resultados de búsqueda de vez en cuando. Si Penguin penalizaba a un sitio web, los SEO tenían que revisar cuidadosamente sus perfiles de enlaces y eliminar los enlaces tóxicos, o agregarlos a una lista de desautorización (una característica introducida en esos días para indicarle a Google qué enlaces entrantes ignorar al calcular el PageRank). Después de auditar los perfiles de enlaces de esa manera, los SEO tuvieron que esperar aproximadamente medio año hasta que el algoritmo Penguin recalcule los datos.
En 2016, Google incluyó a Penguin en parte de su algoritmo de clasificación central. Desde entonces, ha estado trabajando en tiempo real, lidiando algorítmicamente con el spam con mucho más éxito.
Al mismo tiempo, Google trabajó para facilitar la calidad en lugar de la cantidad de enlaces, precisándolo en sus directrices de calidad frente a los esquemas de enlaces.
Bueno, hemos terminado con el pasado de PageRank. ¿Qué está pasando ahora?
En 2019, un ex empleado de Google dijo que el algoritmo PageRank original no se había utilizado desde 2006 y fue reemplazado por otro algoritmo que consumía menos recursos a medida que Internet crecía. Lo cual bien podría ser cierto, ya que en 2006 Google presentó la nueva patente Cómo producir una clasificación de páginas utilizando distancias en un gráfico de enlaces web.
Sí, lo es. No es el mismo PageRank que a principios de la década de 2000, pero Google sigue dependiendo en gran medida de la autoridad de los enlaces. Por ejemplo, un ex empleado de Google, Andrey Lipattsev, mencionó esto en 2016. En un Hangout de preguntas y respuestas de Google, un usuario le preguntó cuáles eran las principales señales de clasificación que utilizaba Google. La respuesta de Andrey fue bastante sencilla.

Puedo decirte cuáles son. Es contenido y enlaces que apuntan a su sitio.
En 2020, John Mueller confirmó eso una vez más:

Sí, utilizamos PageRank internamente, entre muchas, muchas otras señales. No es exactamente igual que el artículo original, hay muchas peculiaridades (por ejemplo, enlaces desautorizados, enlaces ignorados, etc.) y, nuevamente, utilizamos muchas otras señales que pueden ser mucho más potentes.
Como puede ver, PageRank todavía está vivo y Google lo utiliza activamente al clasificar páginas en la web.
Lo interesante es que los empleados de Google siguen recordándonos que hay muchos, muchos, MUCHOS otros factores de clasificación de Google. Pero miramos esto con cautela. Teniendo en cuenta cuánto esfuerzo dedicó Google a combatir el spam de enlaces, podría ser de interés para Google desviar la atención de los SEO de los factores vulnerables a la manipulación (como lo son los vínculos de retroceso) y dirigir esta atención a algo inocente y agradable. Pero como los SEO son buenos leyendo entre líneas, siguen considerando el PageRank como una fuerte señal de clasificación y aumentan los vínculos de retroceso de todas las formas posibles. Todavía usan PBN, practican la construcción de enlaces por niveles, compran enlaces, etc., tal como lo hacía hace mucho tiempo. A medida que viva el PageRank, el spam de enlaces también vivirá. No recomendamos nada de eso, pero esa es la realidad del SEO y tenemos que entenderlo.
Bueno, tienes la idea de que el PageRank actual no es el PageRank que era hace 20 años.
Una de las modernizaciones clave de las relaciones públicas fue pasar del modelo Random Surfer mencionado brevemente anteriormente al modelo Reasonable Surfer en 2012. Reasonable Surfer asume que los usuarios no se comportan de manera caótica en una página y hacen clic solo en los enlaces que les interesan en la página. momento. Digamos que, al leer un artículo de blog, es más probable que haga clic en un enlace en el contenido del artículo que en un enlace de Términos de uso en el pie de página.
Además, Reasonable Surfer puede utilizar potencialmente una gran variedad de otros factores al evaluar el atractivo de un enlace. Todos estos factores fueron revisados cuidadosamente por Bill Slawski en su artículo, pero me gustaría centrarme en los dos factores, que los SEO discuten con más frecuencia. Estos son la posición del enlace y el tráfico de la página. ¿Qué podemos decir sobre estos factores?
Un enlace puede estar ubicado en cualquier lugar de la página: en su contenido, menú de navegación, biografía del autor, pie de página y, de hecho, cualquier elemento estructural que contenga la página. Y las diferentes ubicaciones de los enlaces afectan el valor del enlace. John Mueller lo confirmó, diciendo que los enlaces colocados dentro del contenido principal pesan más que todos los demás:
Esta es el área de la página donde tiene su contenido principal, el contenido del que realmente trata esta página, no el menú, la barra lateral, el pie de página, el encabezado... Entonces eso es algo que tomamos en cuenta y lo intentamos. para utilizar esos enlaces.
Por lo tanto, se dice que los enlaces de pie de página y los enlaces de navegación tienen menos peso. Y este hecho lo confirman de vez en cuando no sólo los portavoces de Google sino también casos de la vida real.
En un caso reciente presentado por Martin Hayman en BrightonSEO, Martin agregó el enlace que ya tenía en su menú de navegación al contenido principal de las páginas. Como resultado, esas páginas de categorías y las páginas a las que enlazaban experimentaron un aumento del tráfico del 25%.
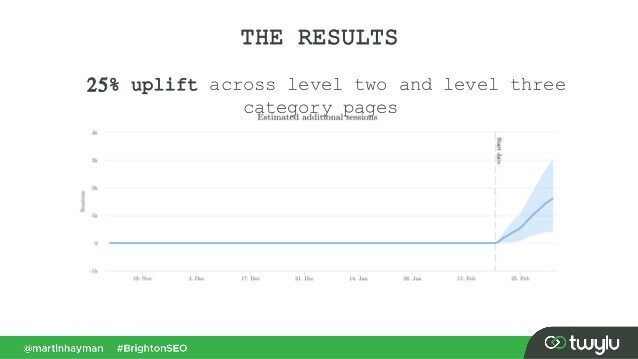
Este experimento demuestra que los enlaces de contenido tienen más peso que cualquier otro.
En cuanto a los enlaces en la biografía del autor, los SEO suponen que los enlaces a la biografía pesan algo, pero son menos valiosos que, por ejemplo, los enlaces de contenido. Aunque no tenemos muchas pruebas aquí excepto lo que dijo Matt Cutts cuando Google estaba luchando activamente contra el exceso de blogs invitados para obtener vínculos de retroceso.
John Mueller aclaró la forma en que Google trata el tráfico y el comportamiento del usuario en términos de pasar enlaces en uno de los Hangouts de Search Console Central. Un usuario preguntó a Mueller si Google considera la probabilidad de hacer clic y la cantidad de clics en un enlace al evaluar la calidad de un enlace. Las conclusiones clave de la respuesta de Mueller fueron:
Google no tiene en cuenta los clics en enlaces ni la probabilidad de hacer clic al evaluar la calidad del enlace.
Google entiende que los enlaces a menudo se agregan al contenido como referencias y no se espera que los usuarios hagan clic en todos los enlaces que encuentran.
Aún así, como siempre, los SEO dudan si vale la pena creer ciegamente todo lo que dice Google y siguen experimentando. Entonces, los chicos de Ahrefs llevaron a cabo un estudio para comprobar si la posición de una página en un SERP está relacionada con la cantidad de vínculos de retroceso que tiene desde páginas de alto tráfico. El estudio reveló que apenas existe correlación. Además, algunas páginas mejor clasificadas resultaron no tener ningún vínculo de retroceso de páginas con mucho tráfico.
Este estudio nos apunta en una dirección similar a las palabras de John Mueller: no es necesario crear vínculos de retroceso que generen tráfico a su página para obtener posiciones altas en un SERP. Por otro lado, el tráfico adicional nunca ha perjudicado a ningún sitio web. El único mensaje aquí es que los vínculos de retroceso con mucho tráfico no parecen influir en la clasificación de Google.
Como recordarás, Google introdujo la etiqueta nofollow en 2005 como una forma de combatir el spam de enlaces. ¿Ha cambiado algo hoy? En realidad, sí.
En primer lugar, Google ha introducido recientemente dos tipos más del atributo nofollow. Antes de eso, Google sugirió marcar todos los vínculos de retroceso que no desea que participen en el cálculo del PageRank como nofollow, ya sean comentarios de blogs o anuncios pagados. Hoy en día, Google recomienda utilizar rel="sponsored" para enlaces pagos y de afiliados y rel="ugc" para contenido generado por el usuario.

Es interesante que estas nuevas etiquetas no son obligatorias (al menos no todavía), y Google señala que no es necesario cambiar manualmente todas las etiquetas rel=”nofollow” a rel="sponsored" y rel=”ugc”. Estos dos nuevos atributos ahora funcionan de la misma manera que una etiqueta nofollow normal.
En segundo lugar, Google ahora dice que las etiquetas nofollow, así como las nuevas, patrocinadas y ugc, se tratan como sugerencias, en lugar de como directivas, al indexar páginas.
Además de los enlaces entrantes, también hay enlaces salientes, es decir, enlaces que apuntan a otras páginas suyas.
Muchos SEO creen que los enlaces salientes pueden afectar las clasificaciones, pero esta suposición se ha tratado como un mito de SEO. Pero hay un estudio interesante que analizar a este respecto.
Reboot Online llevó a cabo un experimento en 2015 y lo volvió a ejecutar en 2020. Querían averiguar si la presencia de enlaces salientes a páginas de alta autoridad influía en la posición de la página en un SERP. Crearon 10 sitios web con artículos de 300 palabras, todos optimizados para una palabra clave inexistente: Phylandocic. Cinco sitios web quedaron sin ningún enlace saliente y cinco sitios web contenían enlaces salientes a recursos de alta autoridad. Como resultado, los sitios web con enlaces salientes autorizados comenzaron a ocupar los primeros puestos, y los que no tenían ningún enlace ocuparon las posiciones más bajas.
.png)
Por un lado, los resultados de esta investigación pueden decirnos que los enlaces salientes influyen en la posición de las páginas. Por otro lado, el término de búsqueda en la investigación es completamente nuevo y el contenido de los sitios web tiene como tema medicina y fármacos. Por lo tanto, es muy probable que la consulta se haya clasificado como YMYL. Y Google ha manifestado muchas veces la importancia de EAT para los sitios web de YMYL. Por lo tanto, los enlaces externos bien podrían haber sido tratados como una señal EAT, lo que demuestra que las páginas tienen contenido objetivamente exacto.
En cuanto a las consultas ordinarias (no YMYL), John Mueller ha dicho muchas veces que no debe tener miedo de vincular su contenido a fuentes externas, ya que los enlaces salientes son buenos para sus usuarios.
Además, los enlaces salientes también pueden ser beneficiosos para el SEO, ya que la IA de Google puede tenerlos en cuenta al filtrar la web contra el spam. Porque las páginas con spam tienden a tener pocos enlaces salientes, si es que tienen alguno. O bien enlazan a páginas del mismo dominio (si alguna vez piensan en SEO) o contienen únicamente enlaces pagos. Entonces, si enlaza a algunos recursos creíbles, le muestra a Google que su página no es spam.
Alguna vez existió la opinión de que Google podría imponerle una penalización manual por tener demasiados enlaces salientes, pero John Mueller dijo que esto sólo es posible cuando los enlaces salientes son obviamente parte de algún esquema de intercambio de enlaces, además el sitio web es en general de mala calidad. Lo que Google quiere decir con "obvio" es en realidad un misterio, así que tenga en cuenta el sentido común, el contenido de alta calidad y el SEO básico.
Mientras exista el PageRank, los SEO buscarán nuevas formas de manipularlo.
En 2012, era más probable que Google lanzara acciones manuales para manipulación de enlaces y spam. Pero ahora, con sus algoritmos antispam bien entrenados, Google puede simplemente ignorar ciertos enlaces spam al calcular el PageRank en lugar de bajar el ranking de todo el sitio web en general. Como dijo John Mueller,
Los enlaces aleatorios recopilados a lo largo de los años no son necesariamente dañinos, también los hemos visto durante mucho tiempo y podemos ignorar todos esos extraños graffitis web de hace mucho tiempo.
Esto también se aplica al SEO negativo cuando su competencia compromete su perfil de vínculo de retroceso:
En general, los tomamos en cuenta automáticamente e intentamos... ignorarlos automáticamente cuando vemos que suceden. En general, sospecho que funciona bastante bien. Veo muy pocas personas con problemas reales al respecto. Así que creo que en general está funcionando bien. Con respecto a desautorizar estos enlaces, sospecho que si son sólo enlaces spam normales que aparecen en su sitio web, entonces no me preocuparía demasiado por ellos. Probablemente lo descubrimos por nuestra cuenta.
Sin embargo, eso no significa que no tengas nada de qué preocuparte. Si los vínculos de retroceso de su sitio web se ignoran demasiado y con demasiada frecuencia, aún tiene muchas posibilidades de realizar una acción manual. Como dice Marie Haynes en su consejo sobre la gestión de enlaces en 2021:

Las acciones manuales están reservadas para casos en los que un sitio que de otro modo sería decente tiene enlaces no naturales que apuntan a él en una escala tan grande que los algoritmos de Google no se sienten cómodos ignorándolos.
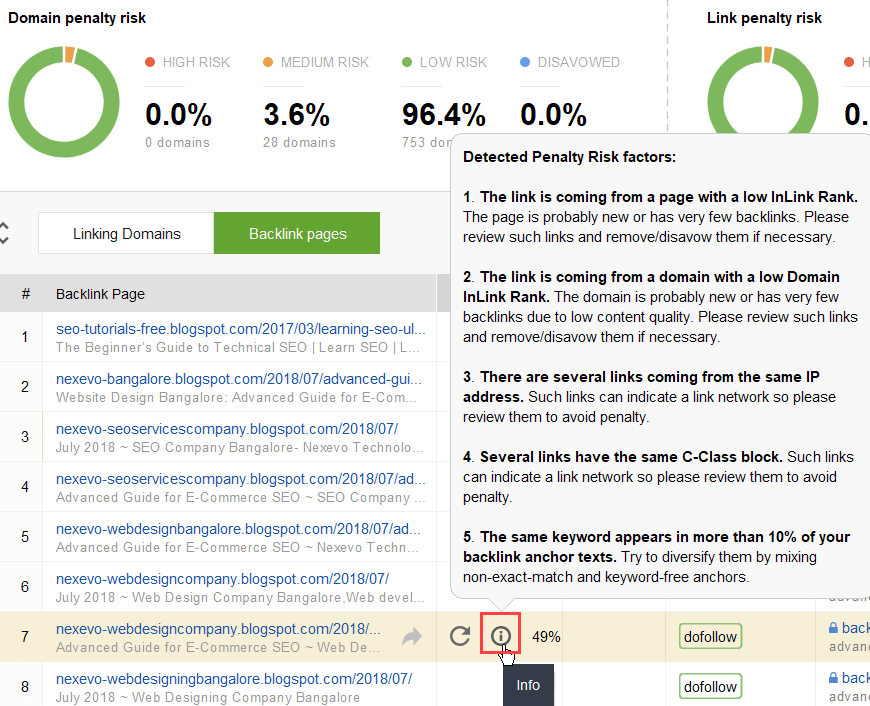
Para intentar descubrir qué enlaces están provocando el problema, lea esta guía sobre cómo verificar la calidad de los vínculos de retroceso. En resumen, puedes utilizar un comprobador de vínculos de retroceso como SEO SpyGlass. En la herramienta, vaya a la sección Perfil de vínculo de retroceso > Riesgo de penalización. Preste atención a los vínculos de retroceso de riesgo alto y medio.
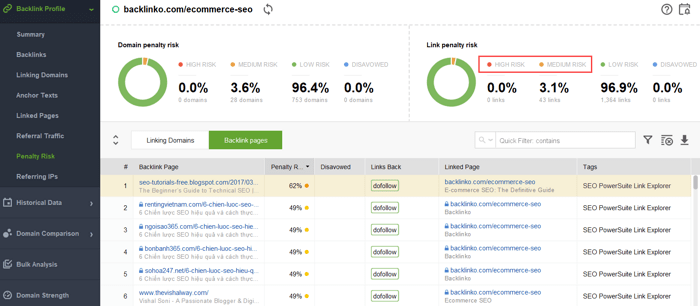
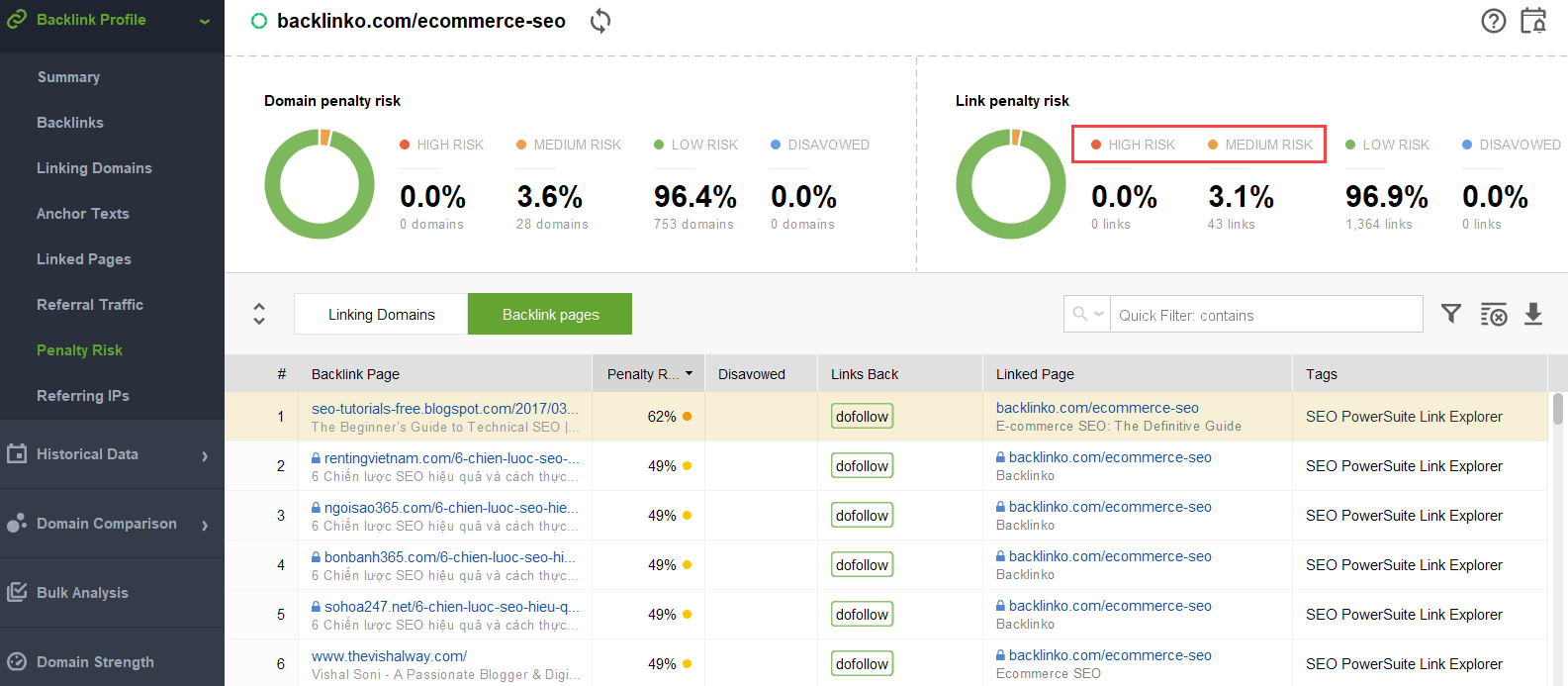
Para investigar más a fondo por qué este o aquel enlace se considera dañino, haga clic en el signo i en la columna Riesgo de penalización. Aquí verá por qué la herramienta consideró que el enlace era malo y decidirá si rechazará un enlace o no.
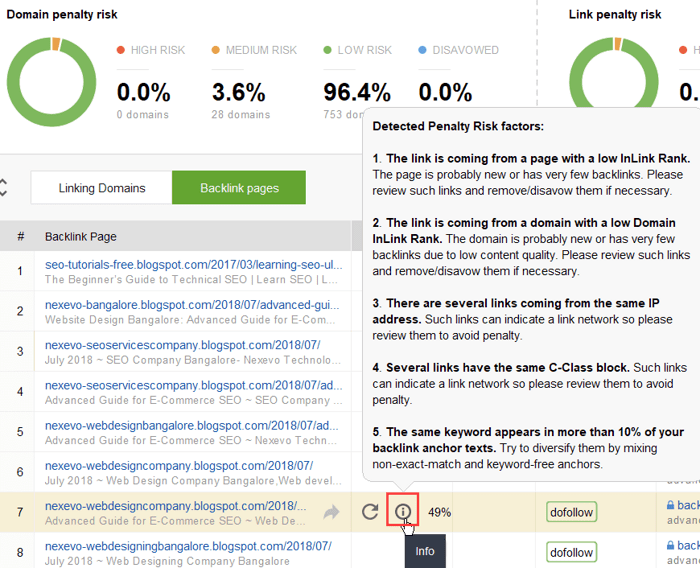
Si decide desautorizar un enlace de un grupo de enlaces, haga clic derecho en ellos y elija la opción Desautorizar vínculos de retroceso:
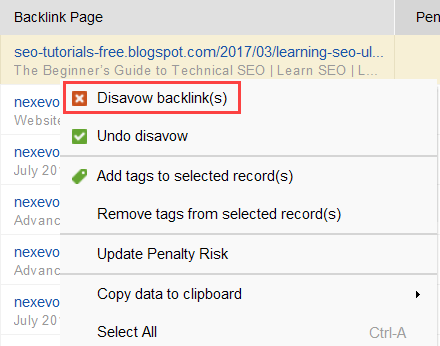
Una vez que haya formado una lista de enlaces para excluir, puede exportar el archivo de desautorización de SEO SpyGlass y enviarlo a Google a través de GSC.
Hablando de PageRank, no podemos dejar de mencionar los enlaces internos. El PageRank entrante es algo que no podemos controlar, pero podemos controlar totalmente la forma en que las relaciones públicas se distribuyen en las páginas de nuestro sitio web.
Google también ha señalado muchas veces la importancia de los enlaces internos. John Mueller subrayó esto una vez más en uno de los últimos Hangouts de Search Console Central. Un usuario preguntó cómo hacer que algunas páginas web sean más potentes. Y John Mueller dijo lo siguiente:
...Puedes ayudar con los enlaces internos. Entonces, dentro de su sitio web, realmente puede resaltar las páginas que desea resaltar más y asegurarse de que estén realmente bien vinculadas internamente. Y tal vez las páginas que no te parezcan tan importantes, asegúrate de que estén un poco menos vinculadas internamente.
Los enlaces internos significan mucho. Le ayuda a compartir el PageRank entrante entre diferentes páginas de su sitio web, fortaleciendo así las páginas de bajo rendimiento y fortaleciendo su sitio web en general.
En cuanto a los enfoques de los enlaces internos, los SEO tienen muchas teorías diferentes. Un enfoque popular está relacionado con la profundidad de los clics en el sitio web. Esta idea dice que todas las páginas de su sitio web deben estar a una distancia máxima de 3 clics desde la página de inicio. Aunque Google también ha subrayado muchas veces la importancia de una estructura superficial de los sitios web, en realidad esto parece inalcanzable para todos los sitios web más grandes que los pequeños.
Un enfoque más se basa en el concepto de vinculación interna centralizada y descentralizada. Como lo describe Kevin Indig:

Los sitios centralizados tienen un flujo de usuario único y un embudo que apunta a una página clave. Los sitios con enlaces internos descentralizados tienen múltiples puntos de contacto de conversión o diferentes formatos para registrarse.
En el caso de los enlaces internos centralizados, tenemos un pequeño grupo de páginas de conversión o una página, que queremos que sea potente. Si aplicamos enlaces internos descentralizados, queremos que todas las páginas del sitio web sean igualmente poderosas y tengan el mismo PageRank para que todas se clasifiquen para sus consultas.
¿Qué opción es mejor? Todo depende de su sitio web y de las peculiaridades del nicho de negocio, y de las palabras clave a las que se dirigirá. Por ejemplo, los enlaces internos centralizados se adaptan mejor a las palabras clave con volúmenes de búsqueda altos y medios, ya que dan como resultado un conjunto reducido de páginas superpoderosas.
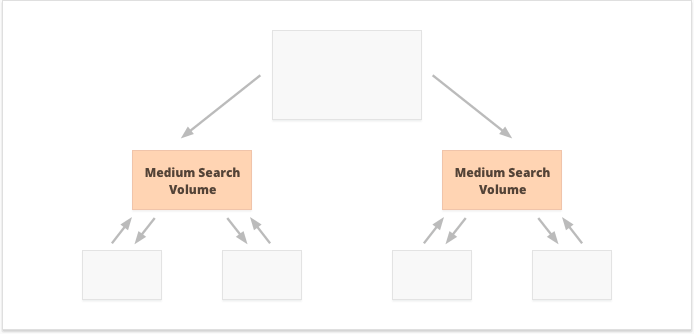
Las palabras clave de cola larga con un volumen de búsqueda bajo, por el contrario, son mejores para los enlaces internos descentralizados, ya que distribuyen las relaciones públicas por igual entre numerosas páginas del sitio web.
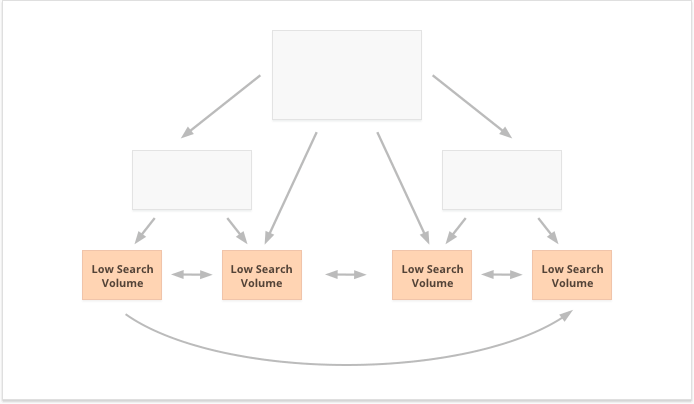
Un aspecto más de los enlaces internos exitosos es el equilibrio de los enlaces entrantes y salientes en la página. En este sentido, muchos SEO utilizan CheiRank (CR), que en realidad es un PageRank inverso. Pero mientras PageRank es el poder recibido, CheiRank es el poder de enlace que se regala. Una vez que calcules PR y CR para tus páginas, podrás ver qué páginas tienen anomalías en los enlaces, es decir, los casos en los que una página recibe mucho PageRank pero avanza un poco más y viceversa.
Un experimento interesante aquí es el aplanamiento de anomalías de enlaces de Kevin Indig. Simplemente asegurarse de que el PageRank entrante y saliente esté equilibrado en cada página del sitio web generó resultados impresionantes. La flecha roja aquí señala el momento en que se solucionaron las anomalías:
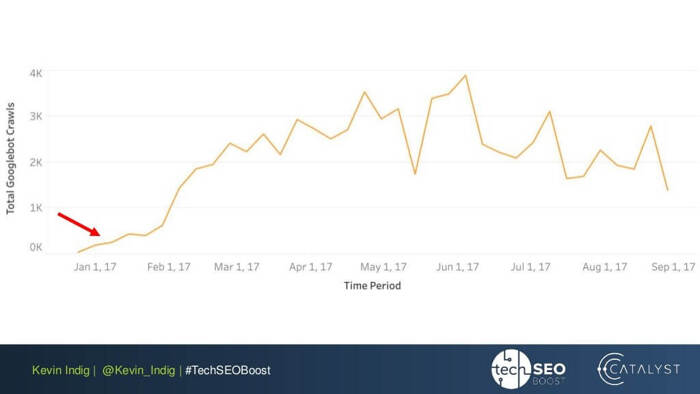
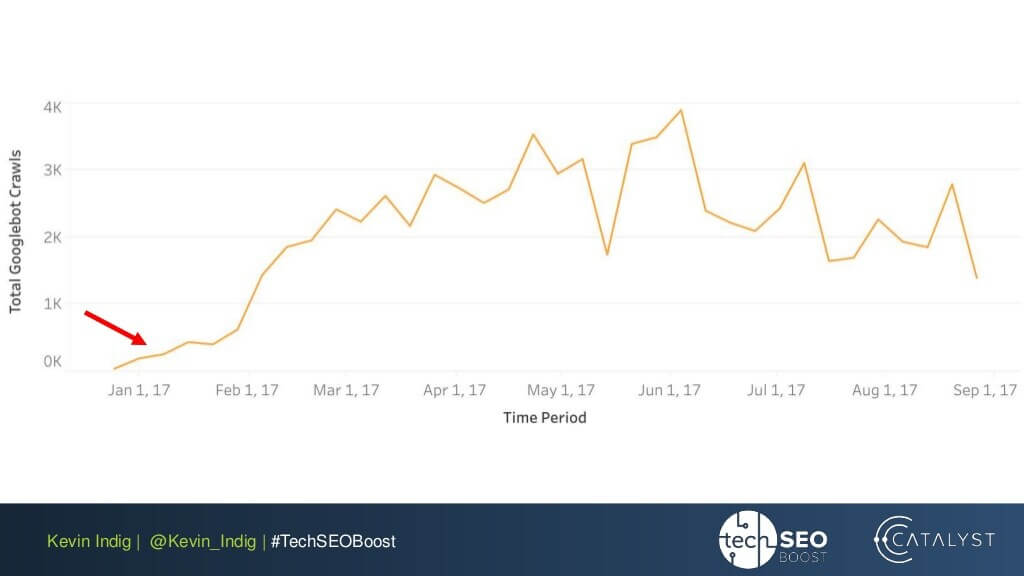
Las anomalías en los enlaces no son lo único que puede dañar el flujo de PageRank. Asegúrese de no quedarse atascado con ningún problema técnico, que podría destruir las relaciones públicas que tanto le costó ganar:
Páginas huérfanas. Las páginas huérfanas no están vinculadas a ninguna otra página de su sitio web, por lo que permanecen inactivas y no reciben ningún enlace. Google no puede verlos y no sabe que realmente existen.
Cadenas de redireccionamiento. Aunque Google dice que las redirecciones ahora pasan el 100% de las relaciones públicas, se recomienda evitar cadenas de redirecciones largas. Primero, de todos modos consumen su presupuesto de rastreo. En segundo lugar, sabemos que no podemos creer ciegamente todo lo que dice Google.
Enlaces en JavaScript no analizable. Como Google no puede leerlos, no pasarán el PageRank.
404 enlaces. Los enlaces 404 no llevan a ninguna parte, por lo que el PageRank tampoco lleva a ninguna parte.
Enlaces a páginas sin importancia. Por supuesto, no puedes dejar ninguna de tus páginas sin ningún enlace, pero las páginas no son iguales. Si alguna página es menos importante, no es racional esforzarse demasiado en optimizar el perfil de enlace de esa página.
Páginas demasiado lejanas. Si una página está ubicada demasiado profunda en su sitio web, es probable que reciba pocas relaciones públicas o ninguna. Ya que es posible que Google no logre encontrarlo e indexarlo.
Para asegurarse de que su sitio web esté libre de estos peligros de PageRank, puede auditarlo con WebSite Auditor. Esta herramienta tiene un conjunto completo de módulos dentro de la sección Estructura del sitio > Auditoría del sitio, que le permiten verificar la optimización general de su sitio web y, por supuesto, encontrar y solucionar todos los problemas relacionados con los enlaces, como los redireccionamientos largos:
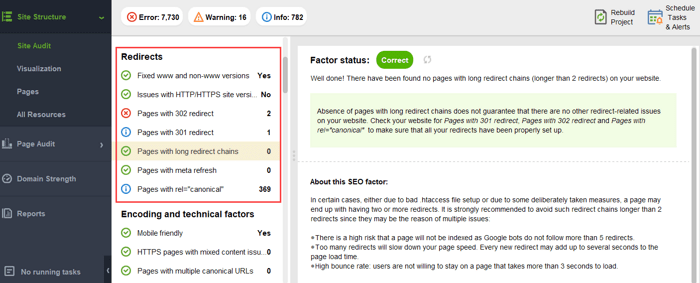
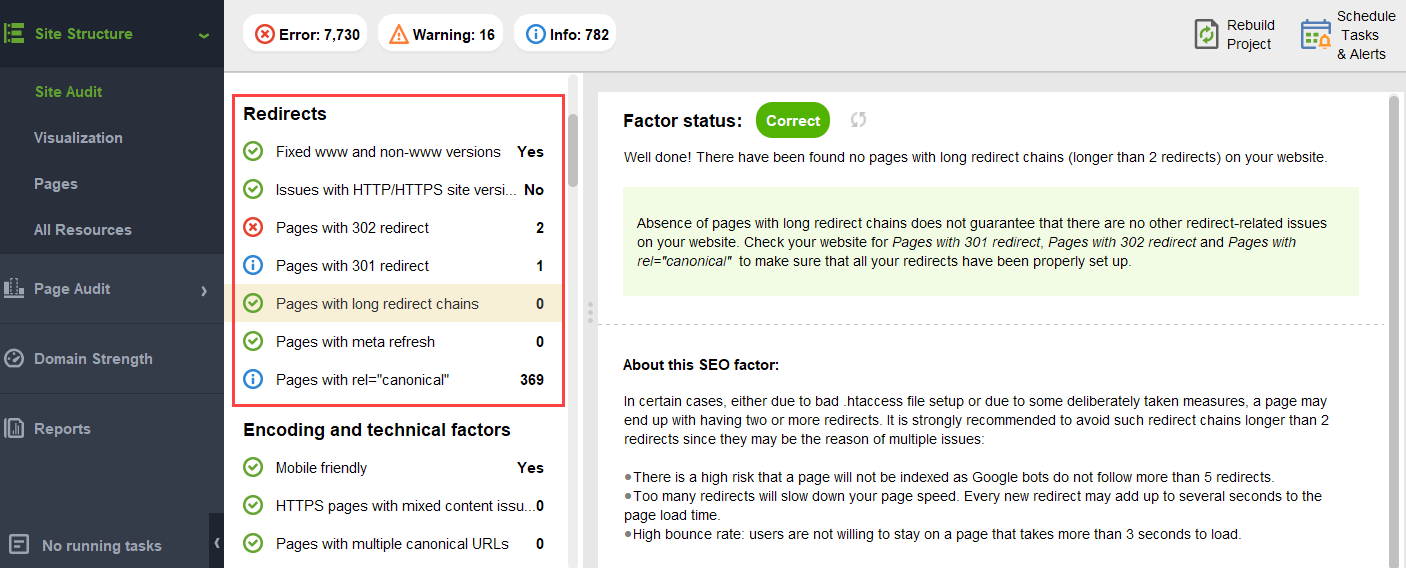
y enlaces rotos:
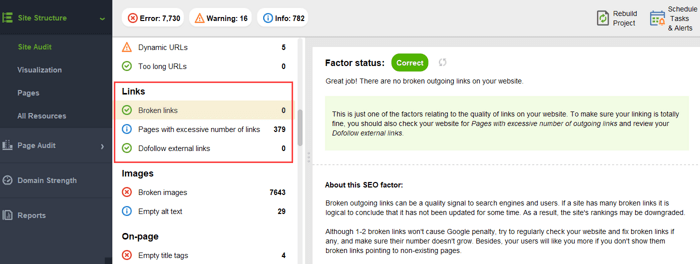
Para comprobar si su sitio tiene páginas huérfanas o páginas que están demasiado distantes, cambie a Estructura del sitio > Visualización:
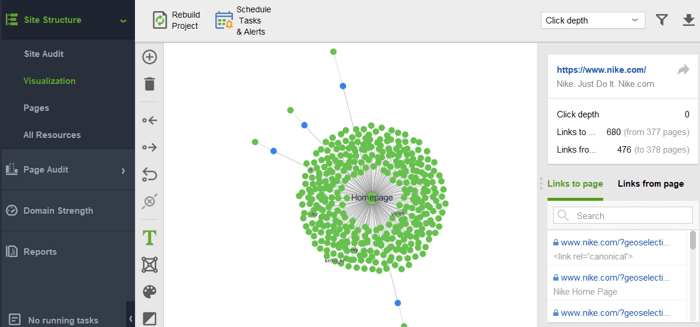
Este año, PageRank cumplió 23 años. Y supongo que es mayor que algunos de nuestros lectores de hoy:) Pero, ¿qué le espera a PageRank en el futuro? ¿Desaparecerá por completo algún día?
Cuando trato de pensar en un motor de búsqueda popular que no utiliza vínculos de retroceso en su algoritmo, la única idea que se me ocurre es el experimento de Yandex en 2014. El motor de búsqueda anunció que eliminar los vínculos de retroceso de su algoritmo podría finalmente detener la manipulación de los spammers de vínculos y ayudar a dirigir sus esfuerzos hacia la creación de sitios web de calidad.
Podría haber sido un esfuerzo genuino por avanzar hacia factores de clasificación alternativos, o simplemente un intento de persuadir a las masas para que abandonaran los enlaces spam. Pero en cualquier caso, apenas un año después del anuncio, Yandex confirmó que los factores de vínculo de retroceso estaban nuevamente en su sistema.
Pero, ¿por qué los vínculos de retroceso son tan indispensables para los motores de búsqueda?
Si bien hay muchos otros puntos de datos para reorganizar los resultados de búsqueda después de comenzar a mostrarlos (como el comportamiento del usuario y los ajustes de BERT), los vínculos de retroceso siguen siendo uno de los criterios de autoridad más confiables necesarios para formar el SERP inicial. Su único competidor aquí son, probablemente, las entidades.
Como dice Bill Slawski cuando se le pregunta sobre el futuro del PageRank:
.png)
Google está explorando el aprendizaje automático y la extracción de hechos y la comprensión de pares de valores clave para entidades comerciales, lo que significa un movimiento hacia la búsqueda semántica y un mejor uso de los datos estructurados y la calidad de los datos.
Aún así, es bastante improbable que Google descarte algo en lo que han invertido decenas de años de desarrollo.
Google es muy bueno en el análisis de enlaces, que ahora es una tecnología web muy madura. Por eso, es muy posible que el PageRank se siga utilizando para clasificar las SERP orgánicas.
Otra tendencia que señaló Bill Slawski fueron las noticias y otros tipos de resultados de búsqueda de corta duración:
Google nos ha dicho que ha dependido menos del PageRank para páginas donde la puntualidad es más importante, como los resultados en tiempo real (como los de Twitter), o para los resultados de noticias, donde la puntualidad es muy importante.
De hecho, una noticia aparece demasiado poco en los resultados de búsqueda como para acumular suficientes vínculos de retroceso. Por eso, Google ha estado y podría seguir trabajando para sustituir los vínculos de retroceso con otros factores de clasificación cuando se trata de noticias.
Sin embargo, por ahora, las clasificaciones de noticias están determinadas en gran medida por la autoridad de nicho del editor, y todavía entendemos la autoridad como vínculos de retroceso:
"Las señales de autoridad ayudan a priorizar información de alta calidad de las fuentes más confiables disponibles. Para hacer esto, nuestros sistemas están diseñados para identificar señales que pueden ayudar a determinar qué páginas demuestran experiencia, autoridad y confiabilidad en un tema determinado, según los comentarios de los evaluadores de búsqueda. "Esas señales pueden incluir si otras personas valoran la fuente para consultas similares o si otros sitios web destacados sobre el tema enlazan con la historia".
Por último, pero no menos importante, me sorprendió bastante el esfuerzo que hizo Google para poder identificar vínculos de retroceso patrocinados y generados por el usuario y distinguirlos de otros vínculos no seguidos.
Si todos esos vínculos de retroceso deben ignorarse, ¿por qué preocuparse por distinguirlos entre sí? Especialmente cuando John Muller sugiere que más adelante Google podría intentar tratar ese tipo de enlaces de manera diferente.
Mi suposición más descabellada aquí fue que tal vez Google esté validando si la publicidad y los enlaces generados por los usuarios podrían convertirse en una señal de clasificación positiva.
Después de todo, la publicidad en plataformas populares requiere presupuestos enormes, y los presupuestos enormes son un atributo de una marca grande y popular.
El contenido generado por el usuario, cuando se considera fuera del paradigma de spam de comentarios, se trata de clientes reales que dan su respaldo en la vida real.
Sin embargo, los expertos con los que me comuniqué no creían que fuera posible:

Dudo que Google alguna vez considere los enlaces patrocinados como una señal positiva.
La idea aquí, al parecer, es que al distinguir diferentes tipos de enlaces, Google intentaría determinar cuáles de los enlaces nofollow se deben seguir para fines de creación de entidades:

Google no tiene ningún problema con el contenido generado por el usuario o el contenido patrocinado en un sitio web; sin embargo, ambos se han utilizado históricamente como métodos para manipular el pagerank. Como tal, se anima a los webmasters a colocar un atributo nofollow en estos enlaces (entre otras razones para usar nofollow). Sin embargo, los enlaces nofollow aún pueden ser útiles para Google para cosas (como el reconocimiento de entidades, por ejemplo), por lo que han señalado anteriormente que Puede tratar esto más como una sugerencia, y no como una directiva como una regla de no permitir robots.txt que estaría en su propio sitio. La declaración de John Mueller fue: "Me imagino que en nuestros sistemas podríamos aprender con el tiempo a tratarlos de manera ligeramente diferente"..” Esto podría referirse a los casos en los que Google trata un nofollow como una sugerencia. Hipotéticamente, es posible que los sistemas de Google puedan aprender qué enlaces nofollow seguir según la información recopilada de los tipos de enlaces marcados como ugc y patrocinados. Nuevamente, esto no debería tener un gran impacto en la clasificación de un sitio, pero en teoría también podría tener un impacto en el sitio al que se vincula.
Espero haber logrado aclarar el papel de los vínculos de retroceso en los algoritmos de búsqueda actuales de Google. Algunos de los datos que encontré mientras investigaba el artículo fueron una sorpresa incluso para mí. Así que espero unirme a su discusión en los comentarios.
¿Alguna pregunta que todavía tengas sin respuesta? ¿Alguna idea que tengas sobre el futuro de PageRank?
| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |






